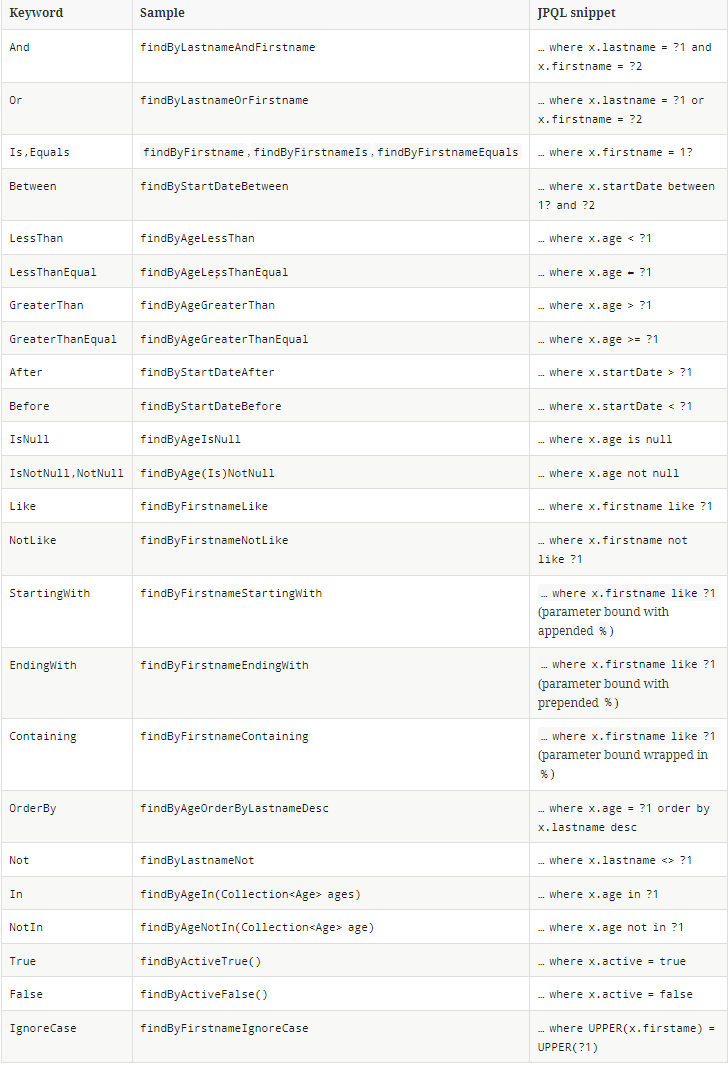
JPA를 사용하여 프로젝트를 구현할 때 스프링 데이터 JPA를 이용하고 repository 인터페이스를 작성하여 CRUD기능을 사용하였을 것이다.
우리는 JPA를 사용하기 위해 Repository를 만들고 CRUD기능을 수행할 수 있다. 하지만 간단한 형식의 엔티티만을 가져올 뿐이지 특정 범위, 특정 경우, 특정 순서 등 복잡한 경우에 적용하기는 힘들다. 이러한 경우는 자세한 sql문을 이용해서 해결할 수 있다. ORM은 엔티티 객체를 대상으로 개발하므로 검색을 위한 sql문도 엔티티 객체를 대상으로 해야 하기에 JPQL을 사용한다. 스프링 데이터 JPA에서는 복잡한 쿼리를 쿼리 메서드를 이용하여 JPQL을 직접 짜는 것이다. 이 글에서는 JPQL에 대해서는 간단한 설명과 파라미터 바인딩에 대해서만 설명하겠다.
JPQL은 객체를 대상으로 검색하는 객체지향 쿼리이며 특정 sql에 의존하지 않는다.
JPA는 우선 JPQL을 읽고 이에 해당하는 SQL문을 만들어 이에 따른 엔터티를 반환할 수 있는 함수를 사용하여 반환을 할 수 있게 된다. JPQL은 SQL과 거의 비슷하다. 여기서 중요한 것은 JPQL은 항상 객체를 별칭으로 사용해야 한다는 것이다. 아래는 간단한 예시이다.

em.createQuery() 메서드에 실행할 JPQL과 반환활 엔티티의 클래스 타입인 Article.class를 넘겨주고 getRssultList() 메서드를 실행하면 JPA는 JPQL을 SQL로 변환해서 데이터베이스를 조회한다. 그리고 조회한 결과로 Article엔티티를 생성해서 반환한다.
그럼 이제 파라미터 바인딩에 대해 설명하겠다.
JDBC는 위치 기준 파라미터 바인딩만을 지원하지만 JPQL은 이름 기준 파라미터 바인딩도 지원한다.
아래는 간단한 예시이다.

위 사진처럼 :title이라는 곳에 setParameter을 이용해서 값을 집어넣을 수 있다. 이름 기준 파라미터이다. 아래는 위치기준 파라미터의 예시이다.

파라미터 바인딩은 악의적인 SQL 인젝션 공격을 예방할 수 있고 JPA 및 데이터베이스는 JPQL을 SQL로 파싱 한 결과를 재사용 가능하다는 점에서 성능 향상을 이뤄낼 수 있다. 이렇기에 필수적으로 파라미터 바인딩을 사용한다고 한다.
우리는 이미 스프링 데이터 JPA를 통해 EntityManager를 직접 호출하지 않고 구현 클래스도 만들지 않으며 CRUD를 편하고 빠르게 하고 있기에 JPQL 또한 스프링 데이터 JPA에 있는 쿼리 메서드에 대해 설명을 하겠다.
쿼리 메서드는 스프링 데이터 JPA에 있는 기능이며 메서드 이름으로 적절한 JPQL 쿼리를 생성한다. 아래는 간단한 예시이다.

이는 latitude와 longitude를 가지고 Article 객체를 찾겠다는 의미이다. 위 메서드를 실행하면 스프링 데이터 JPA는 메서드 이름을 분석해 JPQL을 생성하고 실행한다. 아래는 위 메서드에 해당하는 JPQL이다.
select a from Article a where a.latitede=?1 and a.longitude=?2
아래는 스프링 데이터 JPA 공식 문서에 있는 쿼리 생성 기능이다.
위에서 제공하지 않는 기능을 사용하려면 repository에 @Query 어노테이션을 통해 직접 쿼리를 정의할 수 있다.
이 방식은 애플리케이션 실행 시 문법 오류를 발견할 수 있다. 아래는 사용 예시이다.
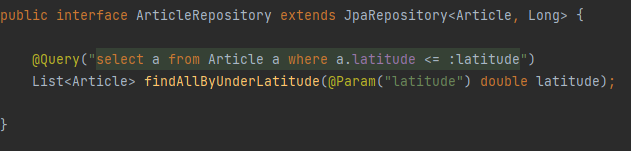
@Query 어노테이션을 붙이고 옵션에 JPQL을 작성하여 findAllByUnderLatitude를 새로 정의하였다. 네이티브 SQL을 사용하려면 natuveQuery = true를 설정한다. 위 사진은 이름 기준 파라미터 바인딩을 사용하였는데 Param 어노테이션을 사용한다.(org.springframework.data.repository.query.Param)
위치 기준 파라미터 바인딩은 Param을 쓰지 않고 파라미터를 작성하면 파라미터 순서로 바인딩한다.
만약 객체가 아니라 여러 값타입들을 조회하고 싶다면 dto 를 만들어서 아래와 같이 작성하면 된다.
@Query("select new rush.rush.dto.ArticleResponse(article.id, article.title, article.content) from Article article "
+ "where article.user.id = :userId")
List <Article> findArticlesByUserId(@Param ("userId") Long userId);
사진에서처럼 new 명령어를 사용하여 반환받을 클래스를 지정해주고 그안에 값들을 넣으면 된다. 반환받을 클래스는 dto이다. 물론 다른 방식도 있지만 이게 가장 가독성있고 편리하여 이 방법만을 적어놓겠다.
그리고 만약 수정, 삭제 쿼리를 작성한 쿼리메서드를 사용할 때는 추가로 @Modifying 를 붙여주어야만 한다.
스프링 데이터 JPA는 두 건 이상이면 List를 통해 컬렉션 인터페이스를 사용하고, 단건이면 반환 타입을 지정한다.
조회 결과가 없을 시 컬렉션은 빈 컬렉션을, 단건은 null을 반환한다. 만약 단건을 지정했는데 두 건 이상이면 javax.persistence.NonUniqueResultException 예외가 발생한다.
마지막으로 페이징 및 정렬을 설명하겠다. 먼저 예시 코드를 보여주겠다.

위와 같이 page를 반환 타입, 마지막 파라미터에 Pagable를 설정한다.

위와 같이 설계한다. 먼저 PageRequest.of 안에 파라미터는 각 첫 번째 페이지, 페이지당 보여줄 데이터, 정렬 함수이다.
그리고 이렇게 만들어진 Pageable 타입의 값을 가지고 findAllByTitle를 실행해서 Page 타입의 결과를 가져오고 이에 맞는 함수를 실행한다. 아래는 함수 리스트이다.
int getNumber(); //현재 페이지
int getSize(); //페이지 크기
int getTotalPages(); //전체 페이지 수
int getNumberOfElements(); //현재 페이지에 나올 데이터 수
long getTotalElements(); //전체 데이터 수
boolean hasPreviousPage(); //이전 페이지 여부
boolean isFirstPage(); //현재 페이지가 첫 페이지 인지 여부
boolean hasNextPage(); //다음 페이지 여부
boolean isLastPage(); //현재 페이지가 마지막 페이지 인지 여부
Pageable nextPageable(); //다음 페이지 객체, 다음 페이지가 없으면 null
Pageable previousPageable(); //다음 페이지 객체, 이전 페이지가 없으면 null
List <T> getContent(); //조회된 데이터
boolean hasContent(); //조회된 데이터 존재 여부
Sort getSort(); //정렬 정보
이렇게 간단하게 JPQL과 쿼리 메서드에 대해 정리해 보았다. 이 글에서는 JPQL을 스프링 데이터 JPA를 이용해서 구현하여 더욱 편하게 구현할 수 있었다. 하지만 스프링 공부를 하기 위해서는 바로 스프링 데이터 JPA로 넘어가지 않고 JPQL도 확실히 공부하는 것이 좋을 것 같다.
참고
https://victorydntmd.tistory.com/204?category=795879
https://ict-nroo.tistory.com/117
https://itmining.tistory.com/139
https://ithub.tistory.com/28
자바 ORM 표준 JPA 프로그래밍-김영한
'JPA' 카테고리의 다른 글
| JPA 임베디드 타입 (0) | 2021.07.22 |
|---|---|
| JPA - 프록시와 연관관계(즉시로딩, 지연로딩, N + 1 문제) (0) | 2021.07.19 |
| JPA 객체 매핑- 연관 관계 (0) | 2021.07.08 |
| JPA H2 데이터베이스 및 서버 실행시 자동 Insert (0) | 2021.06.29 |
| JPA 간략 정리해봄 (0) | 2021.06.29 |


