들어가기
JPA는 데이터 베이스에 있는 객체를 가져올 때 우선 영속성 컨텍스트에 가져오게 된다. 그렇다면 그 객체와 연관된 객체를 가져올 때 어떻게 가져오는가?
경우는 두 가지가 있다.
첫 번째는 그 연관된 객체도 미리 영속성 컨텍스트에 올려놓는 것이다. 이 방식을 즉시 로딩이라 한다.
두 번째는 그 연관된 객체를 사용하는 시점에 가져오는 것이다. 이 방식을 지연 로딩이라 한다.
이 글에서는 이러한 두 가지 로딩 방식에 대해서 '프록시 객체'와 함께 설명할 것이다.
영속성 컨텍스트에 대한 내용이 많이 나오는데, 이에 대한 것은 https://khdscor.tistory.com/110를 참고하길 바란다.
본론
지연 로딩을 이용하기 위해선 실제 객체 대신에 데이터 베이스 조회를 지연할 수 있는 가짜 객체가 필요한데 이것을 '프록시 객체'라고 한다.
진짜 객체를 가져오는 것이 아니라 데이터베이스에 대한 접근 권환을 위임받은 가짜 객체를 놓는다는 것이다.
프록시는 실제 객체를 상속받아서 만들어지고 프록시 객체의 메서드를 호출하면 프록시 객체는 실제 객체의 메서드를 호출한다.
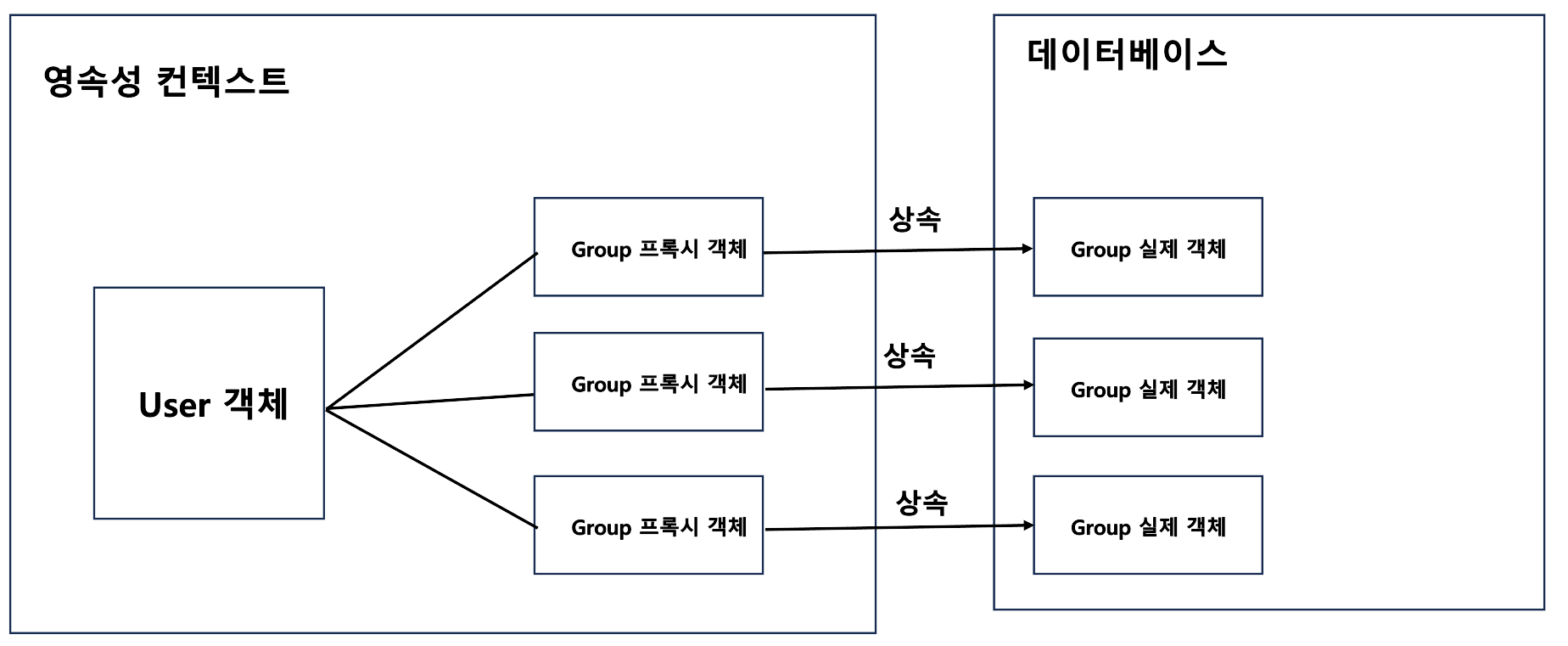
여기서 한가지 알아야 할 것은 프록시 객체는 실제 객체의 식별자 값(primary key)을 가지고 있다는 것이다. 식별자 값을 통해 연관관계를 설정한다. 즉, 프록시 객체는 식별자 값과 메서드들만을 가지고 있는 것이다. 그리고 메서드는 실제 구현 내용을 담고있지 않기때문에 메서드들을 실행시 실제 객체를 영속성 컨텍스트에 가져온 다음, 메서드가 실행된다.
이처럼 프록시는 처음 실제 객체를 조회할 일이 생길 때에 실제 객체를 영속성 컨텍스트에 가져온다. 이를 초기화라고 한다.
초기화는 처음 한번만 일어난다.(참고로 일대 다의 상황에서는 프록시 객체가 여러 개 이므로 프록시 객체 별로 한번씩 일어나면 결국 여러 번의 DB접근이 발생하게 된다.)
두 방법은 각각 다른 상황에서 사용된다. 만약 연관된 객체가 자주 사용하지 않는다면 지연 로딩을 사용하는 것이 좋다. 반대로 자주 사용한다면 즉시 로딩을 이용하는 것이 효율적이다. 아래는 간단한 예시이다.
User와 Group는 서로 일대다의 관계에 있다.
List<User> users = userRepository.findAll(); ----------- 1번
User user = users.get(0);
for (int i=0; i<user.getGroups().size(); i++){
Group group= user.getGroups().get(i);
int id = group.getId(); ---------------- 2번
String groupName = group.getName();---------------- 3번
}
주로 살펴볼 부분은 1, 2, 3 번 부분이다.
즉시 로딩의 경우부터 생각해보자.
1번 부분은 모든 user를 가져오는 메서드이다. 모든 user를 가져오기 위해 1회 조회 쿼리가 나간다. 하지만 즉시로딩은 연관된 객체도 같이 가져온다. user당 group를 가져오기 위해 1회 조회 쿼리가 나가는데, 연관관계가 있는 group들도 같이 가져온다. 하지만 JPQL을 직접 사용한다면 달라진다.
즉시 로딩에서는 JPQL을 사용 시 user를 가져오는 쿼리가 따로 gruop를 가져오는 쿼리가 따로 실행된다. 그렇기에 user가 여러 명일 때는 각각의 user와 연관관계가 있는 group를 가져오기 위해 n번 조회 쿼리가 나가게 된다. 결국 1 + n 번의 조회 쿼리가 나간다.
이제 지연 로딩의 경우를 생각해 보자.
지연 로딩을 이용한다면 user객체를 먼저 가져오고 group객체는 프록시 객체만 가져오며 실제 객체는 필요할 때만 가져오게 된다.
1번 부분은 모든 user를 가져오는 메서드이며 1회의 조회 쿼리가 발생한다. 각각의 user 별로 group은 프록시 객체이므로 추가적인 조회 쿼리를 실행하지 않는다.
문제는 그다음 for문이다. 2번과 3번은 각각 group의 id와 name을 반환하는 메서드이다. 메서드 실행 시 프록시 객체의 초기화가 일어나서 실제 객체를 가져오는 조회 쿼리가 실행된다.
2번을 실행할 때는 id값을 가져오는 것으므로, Foreign Key로서 user를 가져올 때 이미 같이 가져왔기 때문에 실제 객체를 가져오는 쿼리가 발생하지 않는다.
하지만 3번에서는 name을 가져오므로 실제 객체를가져오는 조회 쿼리가 실행된다.
그런데 user가 가지고 있는 모든 group마다 실행하므로 group의 개수만큼 조회 쿼리가 실행된다.
만약 user가 group을 n개 가지고 있다면 1 + n 번의 조회 쿼리가 실행되는 것이다.
위의 예시 코드를 통해 즉시로딩이나 지연로딩이나 이러한 무수한 반복이 일어날 수 있다는 것을 알았다. 이를 N+1 문제라고도 부른다.
N + 1 문제는 성능에 매우 치명적인 문제가 될 수 있기 때문에 무조건 피해야 된다.
결국, 즉시 로딩이나 지연 로딩이나 상황에 따라 문제가 될 수 있고, 더 좋은 수단이 될 수 있기 때문에 상황에 맞게 잘 적용할 수 있어야 한다.
그렇다면 각각의 방식은 어떻게 적용할까? 아래 코드를 한번 봐보자.
public class Group {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
@ManyToOne(fetch= FetchType.EAGER)
@JoinColumn(name = "USER_ID", nullable = false)
private User user;
}
위의 경우는 첫 번째 방식을 적용한 것이고 아래 경우는 두 번째 방식을 적용한 것이다.
public class Group {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
@ManyToOne(fetch= FetchType.LAZY)
@JoinColumn(name = "USER_ID", nullable = false)
private User user;
}
둘의 차이는 @ManyToOne에서 fetch 옵션을 어떻게 지정했는지 뿐이다. 만약 FetchType.EAGER로 설정한다면 즉시 로딩을 적용한 것으로 Group을 가져올 때 User의 실제 객체를 같이 가져오게 된다.
FetchType.LAZY로 설정한다면 지연 로딩을 적용한 것으로 Group을 가져올 때 User의 프록시 객체를 가져오게 된다.
@ManyToOne, @OneToOne은 기본 값이 즉시로딩이다.
@OneToMany, @ManyToMany는 기본 값이 지연 로딩이다.
지연 로딩으로 설정하고 N+1 문제가 발생한다면, 페치 조인을 사용해서 해결할 수 있다. 페치 조인은 SQL 조인을 사용해서 연관된 엔티티를 함께 조회하므로 N+1 문제가 발생하지 않는다.
아래의 JPQL 예시를 보자.
select u from User u join fetch u.groups
실행된 SQL은 아래와 같다.
SELECT U.*, G.* FROM USER U
INNER JOIN GROUPS G ON U.ID = G.USER_ID
결국 처음에 가져올 때 필요한 데이터들을 한 번에 가져오게 되므로 N+1문제를 해결할 수 있다.
페치 조인은 매우 유용하게 사용될 수 있고 SQL 호출 횟수를 줄여 성능을 최적화할 수 있다.
참고로 이 예제는 일대다 조인을 했으므로 결과가 늘어나서 중복된 결과가 나타날 수 있다. 따라서 JPQL의 DISTINCT를 사용해서 중복을 제거하는 것이 좋다.
페치 조인에 대해 몇 가지 더 알아보면 우선 JPA에서는 페치 조인 대상에는 별칭을 줄 수 없다. 하지만 하이버네이트를 포함한 몇몇 구현체들은 페치 조인에 별칭을 지원한다.
그리고 둘 이상의 컬렉션을 페치 할 수 없다. 이는 oneToMany 관계일 때 Many 부분을 페치 조인으로 가져오는 것은 한 번만 가능하다는 의미로 카티전 곱의 위험이 있기에 막아놓았다. 구현체에 따라 되기도 하는데 컬렉션 * 컬렉션의 카티젼 곱이 되지 않도록 주의해야 한다.
그리고 컬렉션을 페치 조인하면 페이징 API를 사용할 수 없다. 일대일이나 다대일 같은 단일 값 연관 필드들은 가능하지만 일대다는 페이징 API를 사용할 수 없다. 하이버네이트에서 컬렉션을 페치 조인하고 페이징 API를 사용하면 경고 로그를 남기면서 메모리에서 페이징 처리를 한다. 데이터가 적으면 상관없겠지만 데이터가 많으면 성능 이슈와 메모리 초과 예외가 발생할 수 있어서 위험하다.
결론
이렇게 간단한 예시를 통해 즉시 로딩과 지연 로딩, 프록시 객체에 대해 알아보았다. 어느 방법이 무조건 정답이라고 할 수는 없으므로 상황에 맞게 잘 적용하여 사용하면 좋을 것이다.
마지막으로 내가 프로젝트에서 실수했던 한 가지를 말해주면 페치조인을 join fetch만 하게 되면 inner join이 발생하는 것과 같은 의미이며, 연결된 것들만 가져온다.
예를 들어 User엔티티에 @OneToMany로 Group엔티티를 지정하였다고 하자.
연결된 엔티티도 함께 가져오고 싶어서 join fetch를 쓴다면 User안에 Group이 null이 아닌 경우(User가 속한 Group이 한 개 이상 있는 경우)의 User만 가져오게 되는 것이다. 하지만 상황에 따라 Group이 있든 없든지 상관없이 모든 User을 가져오고 싶을 때가 있다.
이럴 땐 left join fetch로 표기하여 해결할 수 있다. 이는 left outer join 이 발생하게 된다.
끝으로 한 가지 말하자면 로딩 전략은 기본으로 지연 로딩(LAZY)으로 설정을 하고 최적화가 필요할 때만 페치 조인을 적용하는 것이 효과적이라고 한다.
앞으로 프로젝트를 진행할 때 기본으로 지연 로딩을 설정해야겠다.
참고
자바 ORM 표준 JPA 프로그래밍 - 김영한
https://jyami.tistory.com/22
'JPA' 카테고리의 다른 글
| JPA setter을 만들지 않아야 하는 이유 (0) | 2021.07.22 |
|---|---|
| JPA 임베디드 타입 (0) | 2021.07.22 |
| JPA 객체 매핑- 연관 관계 (0) | 2021.07.08 |
| JPA H2 데이터베이스 및 서버 실행시 자동 Insert (0) | 2021.06.29 |
| JPA 간략 정리해봄 (0) | 2021.06.29 |

