들어가기
예전에 JPA를 Spring Data JPA를 통해 다루면서 repository.save()를 할 시 반환 값으로 Primary Key 값이 포함된 객체를 반환하는 것에 의문이 생겼던 적이 있다. auto_increment 전략을 사용하기에 DB에 데이터가 들어간 이후에 Primary Key가 정해지기 때문이다.
DB에 접근하기 전 영속성 컨텍스트에 데이터가 있으면 DB를 조회하지 않고 영속성 컨텍스트에서 데이터를 조회한다.
그리고 데이터를 저장 시 영속성 컨텍스트에 '쓰기 지연'이라는 기능 덕분에 INSERT 문을 모아두었다가 트랜잭션이 끝났을 때 한꺼번에 DB로 전송하도록 되어 있다.
그렇다면 repository.save()를 할 경우 inesrt 문은 트랜잭션이 끝났을 때 실행될 텐데 어떻게 반환하는 객체에 Primary Key가 있을 수 있는 것인가?
정답을 미리 말하자면 INDENTITY 전략으로 repository.save()를 진행 시 바로 DB에 저장 후 영속성 컨텍스트에 Primary Key를 포함한 객체를 둔다. 그렇기에 아무 문제 없이 영속성 컨텍스트에서 객체를 가져올 수 있는 것이다.
하지만 위 전략을 통해 엔티티 저장 시 DB를 1번 접근해야 된다는 단점이 있다.
이 글에서는 위 문제와 더불어 이러한 영속성 컨텍스트에 특징과 어떻게 사용되는 지를 간단하게 다뤄볼 것이다.
이 글은 '자바 ORM 표준 JPA 프로그래밍 - 김영한'을 참고하여 작성하였다.
본론
영속성 컨텍스트(Persistence Context)란?
들어가기에 앞서 JPA하면 빠질 수 없는 영속성 컨텍스트에 대해 간단하게 알아보자.
영속성 컨텍스트는 서버와 데이터베이스 사이에 엔티티를 저장하는 환경으로, 엔티티를 저장하거나 조회하면 엔티티 매니저는 영속성 컨텍스트에 엔티티를 보관하고 관리한다.
영속성 컨텍스트는 논리적인 개념에 가깝고 눈에 보이지도 않는데, 이러한 영속성 컨텍스트는 엔티티 매니저를 생성할 때 하나씩 만들어진다. 엔티티 매니저(EntityManager)는 내부적으로 데이터베이스 커넥션 풀을 사용하여 DB에 접근하기 위해 필요한 것으로 Transaction이 수행될 때마다 생성된다. 즉, 스레드(사용자 요청)마다 하나의 엔티티 매니저가 있고 영속성 컨텍스트가 있고, 요청마다 공유하면 안 된다.
JPA로 엔티티 조회 시 아래의 그림과 같이 DB에 접근하기 전 영속성 컨텍스트에 엔티티가 있는지 먼저 확인하는 과정을 거친다.
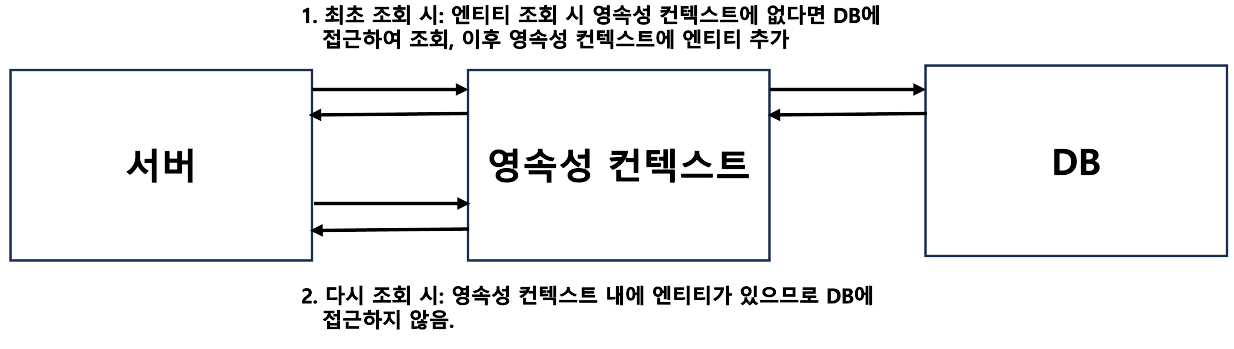
영속성 컨텍스트의 활용 - 엔티티 조회(select)
영속성 컨텍스트에 엔티티가 저장된 상태를 '영속' 상태라고 한다.
위에서 언급했다시피 엔티티를 조회할 시 영속성 컨텍스트에 접근을 하는데, 엔티티가 없다면 DB에 접근하여 엔티티를 조회하고, 엔티티를 영속성 컨텍스트에 저장한다. 영속성 컨텍스트는 내부에 캐시를 가지고 있으며 이를 '1차 캐시'라고 한다. 영속 상태의 엔티티는 모두 이곳에 저장된다.
단순 조회뿐만이 아니라 저장, 수정, 삭제 시에도 영속성 컨텍스트를 활용하게 된다.
그렇다면 영속성 컨텍스트 내에선 엔티티들을 어떻게 구분할까?
엔티티 생성 시 @Id로 테이블의 Primary Key와 매핑한 식별자 값으로 구분한다. 따라서 영속 상태의 엔티티는 식별자 값을 가져야 한다. 식별자 값이 없다면 예외가 발생한다. 이는 데이터베이스 내의 테이블과 영속성 컨텍스트 내의 엔티티가 일치해야 한다는 것을 보여준다.
아래와 같이 @Id로 매핑한 식별자와 엔티티 인스턴스 값을 가지는 Map 형식을 가진다.

만약 조회 메서드를 호출 시 영속성 컨텍스트 내 1차 캐시에 식별자에 해당하는 엔티티가 있다면 DB에 접근하지 않고 1차 캐시에서 바로 조회할 수 있다.
그런데 엔티티를 영속성 컨텍스트에 가져오면 연관 관계에 있는 엔티티는 어떻게 할까?
연관 관계의 엔티티를 가져오는 방법에는 '즉시 로딩'과 '지연 로딩'이 있다.
즉시 로딩은 연관된 엔티티도 영속성 컨텍스트에 같이 이동시키는 것이고, 지연 로딩은 실제 객체를 상속받는 '프록시 객체'라는 가짜 객체를 영속성 컨텍스트에 이동시키는 것이다. 프록시 객체는 식별자 값과 메서드만을 가지고 있기에 식별자를 제외한 다른 필드 값을 요청 시 실제 객체를 영속성 컨텍스트에 이동시킨다. 이를 '프록시의 초기화'라고 한다.
자세한 내용은 https://khdscor.tistory.com/14를 참고하길 바란다.
JPA - 프록시와 연관관계(즉시로딩, 지연로딩, N + 1 문제)
들어가기 JPA는 데이터 베이스에 있는 객체를 가져올 때 우선 영속성 컨텍스트에 가져오게 된다. 그렇다면 그 객체와 연관된 객체를 가져올 때 어떻게 가져오는가? 경우는 두 가지가 있다. 첫 번
khdscor.tistory.com
영속성 컨텍스트의 또 다른 특징으로는 영속된 엔티티는 동일성을 보장한다.
흔히 동일성과 동등성이라는 단어를 들어보았을 것이다.
동일성(identity)은 실제 인스턴스가 같다는 의미로, 실제 값과 더욱이 주소 값도 일치한다.
동등성(equality)은 실제 인스턴스가 다를 수 있지만 인스턴스가 가지고 있는 값이 같다는 것을 의미한다.
두 값을 비교할 때 '(a==b)'와 'a.equals(b)' 방식을 보았을 것이다. (a==b)이 동일성을 비교하고, a.equals(b)가 동등성을 비교한다. 조회 메서드를 통해 영속성 컨텍스트에 가져온 엔티티는 매번 다시 조회를 할때마다 같은 엔티티 인스턴스가 반환된다. 결국, 조회된 엔티티들은 동일성을 보장한다.
참고로 엔티티가 아닌 스칼라 조회일 경우 영속성 컨텍스트에 저장되지 않는다. 영속성 컨텍스트에는 엔티티만 저장되기 때문이다.
영속성 컨텍스트의 활용 - 엔티티 저장(insert)
엔티티를 저장할 때는 어떨까?
영속성 컨텍스트는 트랜잭션이 수행될 때 생성되고 트랜잭션이 커밋될 때 사라진다.(예외는 있다. ex. OSIV)
엔티티를 저장하는 JPA 메서드 실행 시 데이터베이스에 바로 저장하지 않고 영속성 컨텍스트 내부 1차 캐시에 엔티티를 저장하고 쿼리 저장소에 INSERT SQL을 모아둔다. 그리고 트랜잭션을 커밋할 때 모아둔 쿼리를 한 번에 데이터베이스로 보내는데, 이를 '쓰기 지연'이라고 한다.
트랜잭션을 커밋하는 순간 가장 먼저 영속성 컨텍스트에 새로 저장된 엔티티를 데이터베이스에 동기화하는데, 이것을 플러시(flush)라고 한다. 플러시는 영속성 컨텍스트의 변경 내용을 동기화하는데 이때 등록, 수정, 삭제한 엔티티를 데이터베이스에 반영한다.
이는 1차 캐시뿐만 아니라 INSERT SQL을 모아둔 쓰기 지연 SQL 저장소에 모인 쿼리를 데이터베이스에 보내기에 변경 내용을 데이터베이스에 동기화할 수 있는 것이다. 이후 실제 데이터베이스 트랜잭션을 커밋한다.

플러시를 호출하는 방법이 트랜잭션을 커밋하는 방법만 있는 것은 아니다.
em.flush()를 직접 호출하거나 JPQL 쿼리를 실행 시 자동으로 호출된다.
JQPL을 실행 시 플러시가 호출되는 이유는 무엇일까?
만약 엔티티를 조회하여 영속성 컨텍스트에 보관하고 있다고 하자. 이후 엔티티를 수정을 하면 영속성 컨텍스트에 있는 엔티티만 변경이 되고 데이터베이스에 반영되지는 않는다.(아래에서 수정 부분에서 설명 예정)
그런데 JPQL 쿼리로 데이터베이스에서 해당 엔티티를 직접 요청하면 어떻게 될까?
수정되기 전의 엔티티가 조회될 것이다. 이는 무결성을 위반하는 것이다.
이러한 것을 방지하고자 JPQL 쿼리 실행 시 영속성 컨텍스트와 데이터베이스의 동기화를 위해 플러시가 자동으로 일어난다.
참고로 성능 항상을 위해 플러시가 일어나지 않도록 할 수 있다.
@Transactional(readOnly = true)로 설정을 하면 트랜잭션이 끝나도 플러시가 호출되지 않는다.
아래와 같이 쿼리힌트로 플러시 모드를 COMMIT로 설정하면 해당 JPQL 쿼리를 실행해도 플러시가 호출되지 않는다.
@QueryHints(value = { @QueryHint(name = org.hibernate.annotations.QueryHints.FLUSH_MODE, value = "COMMIT") })
이제 서론에서 겪은 문제를 봐보자.
문제는 save() 시 어떻게 식별자 값이 포함된 객체를 반환하는 것인가였다.
엔티티의 식별자 값을 정하는 방법은 데이터베이스 별 사용하는 전략마다 다르다.
예를 들면 MYSQL에서 주로 사용하는 IDENTITY 전략은 데이터베이스가 기본 키를 자동으로 생성해 준다.
엔티티는 영속상태가 되려면 식별자 값이 무조건 필요하다.
결국 영속성 컨텍스트에 식별자 값이 있는 상태로 엔티티가 존재하기 위해선 데이터베이스에 한번 저장 후 다시 가져와야 한다.
이렇듯 IDENTITY 전략으로 엔티티 생성 메서드를 호출 시 데이터베이스에 INSERT SQL이 즉시 전달이 된 후 영속성 컨텍스트에 가져오는 것이다.
따라서 이 전략은 쓰기 지연이 동작하지 않는다.
영속성 컨텍스트의 활용 - 엔티티 수정(update)
엔티티 저장에 추가로 쓰기 지연 SQL 저장소에는 엔티티 수정, 삭제 쿼리도 저장된다.
엔티티 수정 먼저 얘기해 보자.
엔티티를 조회하면 영속성 컨텍스트 내 1차 캐시에 엔티티가 저장된다. 그렇기에 엔티티를 다시 가져올 때 데이터베이스를 거치치 않아도 된다.
여기서 놀라운 점은 조회한 엔티티를 변경하면 따로 UPDATE 쿼리를 날리지 않아도 트랜잭션을 커밋하면 데이터베이스에 반영이 된다는 점이다.
JPA는 엔티티를 영속성 컨텍스트에 보관할 때, 최초 상태를 복사해서 저장해 두는데 이것을 '스냅샷'이라고 한다.
플러시 시점에 스냅샷과 엔티티를 비교하여 변경된 부분을 찾고, 만약 있다면 수정 쿼리를 생성해서 쓰기 지연 SQL 저장소에 보낸다. 이후 트랜잭션이 커밋할 때 SQL을 데이터베이스에 보낸 후 데이터베이스 트랜잭션이 커밋되면서 데이터 변경이 이루어진다.
이렇듯 엔티티의 변경사항을 데이터베이스에 자동으로 반영하는 기능을 '변경 감지'라고 한다.
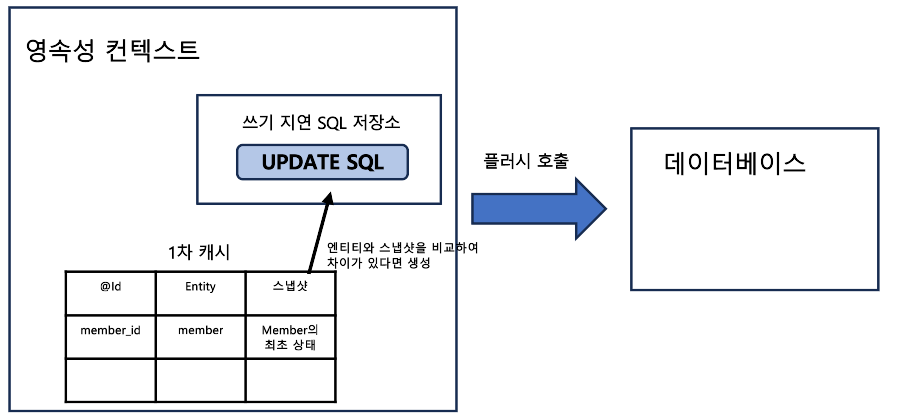
기본적으로 스냅샷이 같이 사용되지만 성능 향상을 위해 스냅샷을 사용하지 않도록 할 수 있다. 아래의 쿼리힌트를 적용하면 스냅샷을 사용하지 않게 되어 메모리 최적화를 이룰 수 있다.
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value = "true"))
참고로 데이터베이스에서 수정쿼리가 생성될 때는 엔티티의 모든 필드를 업데이트하는 쿼리가 생성된다. 그 이유는 어떤 필드를 수정하든 간에 수정쿼리는 항상 같기 때문에 애플리케이션 로딩 시점에 수정 쿼리를 미리 생성해 두고 재사용할 수 있다. 데이터베이스에 동일한 쿼리를 보내면 데이터베이스는 이전에 한 번 파싱 된 쿼리를 재사용할 수 있다.
만약 이러한 방식이 원하지 않다면 @org.hibernate.annotations.DynamicUpdate 어노테이션을 사용할 수 있는데, 수정된 필드만을 변경하는 수정 쿼리를 생성하게 된다. (보통 30개 이상의 필드를 가진 경우, 위 어노테이션을 사용하는 것이 성능 상 유리하다고 한다.)
영속성 컨텍스트의 활용 - 엔티티 삭제(delete)
그렇다면 엔티티를 삭제할 때는 어떨까?
JPA에서 엔티티를 삭제하기 위해선 우선 엔티티를 조회해야 한다.
간혹 ' 스프링 데이터 JPA를 통해 deleteById() 메서드를 호출할 때 매개 변수로 id만을 요구하는 것을 보고 엔티티를 조회하지 않아도 된다'라고 오해할 수도 있다. 이는 잘못된 사실이고 deleteById() 메서드를 보면 내부에서 findById()를 시행 후 delete() 메서드를 실시하는 것을 알 수 있다.
아래 스프링 데이터 JPA가 제공하는 공통 인터페이스의 구현체인 SimpleJpaRepository에 있는 deleteById() 메서드가 어떻게 구현되어 있는지 보여준다.
org.springframework.data.jpa.repository.support.SimpleJpaRepository
@Transactional
public void deleteById(ID id) {
Assert.notNull(id, "The given id must not be null!");
this.delete(this.findById(id).orElseThrow(() -> {
return new EmptyResultDataAccessException(String.format("No %s entity with id %s exists!", this.entityInformation.getJavaType(), id), 1);
}));
}
위와 같이 deleteById는 결국 findById를 한 후 delete를 하는 것을 알 수 있다.
아래는 delete 구현체 코드로 참고하길 바란다.
@Transactional
public void delete(T entity) {
Assert.notNull(entity, "Entity must not be null!");
if (!this.entityInformation.isNew(entity)) {
Class<?> type = ProxyUtils.getUserClass(entity);
T existing = this.em.find(type, this.entityInformation.getId(entity));
if (existing != null) {
this.em.remove(this.em.contains(entity) ? entity : this.em.merge(entity));
}
}
}
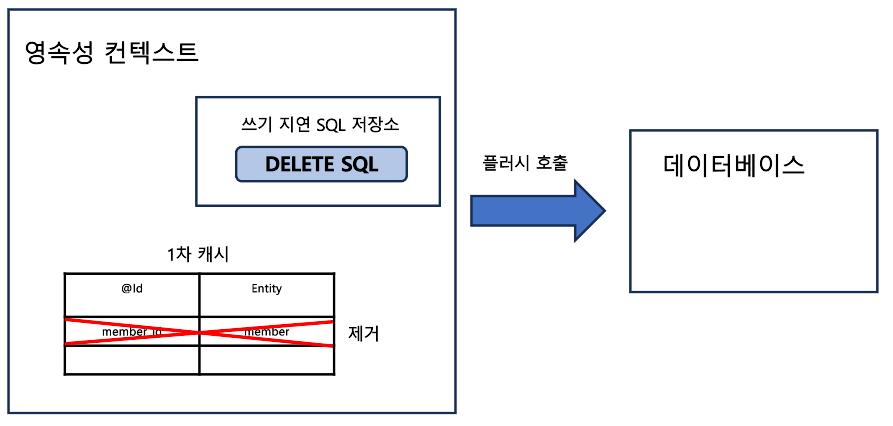
delete 메서드를 실행하면 em.remove가 실행되는데, 이는 엔티티 저장, 수정과 마찬가지로 데이터베이스에 삭제 쿼리를 바로 보내지 않고 쓰기 지연 SQL 저장소에 등록한다. 물론 1차 캐시에 있는 엔티티는 제거된다.
이후 트랜잭션을 커밋하면 플러시가 호출되어 실제 데이터베이스에 삭제 쿼리를 전달한다.
결론
이렇게 영속성 컨텍스트에 대해 간단하게 알아보았다. 영속성 컨텍스트는 엔티티 조회, 삽입, 수정, 삭제 시 활용하고 있으며 아래와 같은 특징들을 가지고 있다.
- 1. 1차 캐시
- 2. 동일성 보장
- 3. 쓰기 지연
- 4. 지연 로딩
- 5. 변경 감지
그리고 IDENTITY 전략을 사용할 경우 영속성 컨텍스트에 쓰기 지연이 발생하지 않아서 엔티티 삽입 메서드 실행 시 INSERT 쿼리를 즉시 데이터베이스로 실행한다는 것을 알았다.
영속성 컨텍스트는 JPA에 핵심 기능이라고 할 수 있을 만큼 매우 큰 영향력을 가지고 있다.
이 글에서만 머물지 않고 더 자세히 공부해 나가야겠다.
참고
자바 ORM 표준 JPA 프로그래밍 - 김영한
https://hwanchang.tistory.com/7
Spring Data JPA 사용 시 deleteById 와 delete 의 차이
Spring Data 란? Spring Data’s mission is to provide a familiar and consistent, Spring-based programming model for data access while still retaining the special traits of the underlying data store. It makes it easy to use data access technologies, relati
hwanchang.tistory.com
https://dodeon.gitbook.io/study/kimyounghan-spring-data-jpa/05-spring-data-jpa
스프링 데이터 JPA 분석 - dodeon
스프링 데이터 JPA는 등록, 수정, 삭제 등 변경 메서드를 트랜잭션 처리한다.
dodeon.gitbook.io
SimpleJpaRepository (Spring Data JPA Parent 3.2.1 API)
java.lang.Object org.springframework.data.jpa.repository.support.SimpleJpaRepository Type Parameters: T - the type of the entity to handle ID - the type of the entity's identifier All Implemented Interfaces: JpaRepository , JpaSpecificationExecutor , JpaRe
docs.spring.io
How to set FlushMode to COMMIT in SPRING DATA for a single method
I would like to make a single method to run without the FlushMode.ALWAYS. So I need to setFlushMode(FlushMode.COMMIT) but I don't know how to do that and I'm starting to think that it's not possible
stackoverflow.com
https://khdscor.tistory.com/20
JPA - 읽기 전용으로 데이터를 조회하여 성능 향상(메모리, 속도)
들어가기 JPA를 사용하면서 영속성 컨텍스트를 통해 1차 캐시 및 쓰기 지연 등 여러 가지 이점을 얻을 수 있었다. 그런데 조회 기능만을 사용하는 상황에서는 단순히 읽기 전용 기능으로 데이터
khdscor.tistory.com
'JPA' 카테고리의 다른 글
| JPA를 활용한 연관관계 데이터 저장: getReferenceById()를 쓰는 이유 (0) | 2024.07.29 |
|---|---|
| QueryDsl를 사용해보자.(With Spring boot 3.x.x, JPA) (0) | 2023.11.29 |
| JPA 양방향 연관관계 일 때의 저장 및 연관관계 편의 메서드 (0) | 2021.12.14 |
| JPA column에 list를 넣는 방법(String 변환, @ElementCollection) (0) | 2021.12.11 |
| 스프링부트 With JPA - mysql 연동 (0) | 2021.12.06 |


