들어가기
이 글에서는 간단하게 Springboot에 Redis를 적용하여 캐시 기능을 구현하는 과정을 설명할 것이다.
Redis에 대한 기본적인 내용은 https://khdscor.tistory.com/98를 참고하길 바란다.
springboot with redis
1. RedisTemplate를 통한 cache 사용
우선 간단하게 캐시에 대해서 설명해 보겠다.
캐시(cache)란 데이터를 미리 복사해 놓은 임시 저장소를 의미한다. 사실, 캐시는 꽤나 자주 사용되는 용어이다. 당장에 컴퓨터 저장장치 계층구조만 봐도 캐시라는 용어가 나온다.
이러한 캐시는 성능향상에 큰 이점이 있는데 바로 DB접근을 줄일 수 있는 것이다. redis는 인메모리 DB로 디스크가 아닌 메모리에 데이터를 저장한다. 이러한 redis에 특징을 활용하여 캐시 공간으로서 사용할 수가 있다. 우선 사용자의 첫 요청 시에는 DB에 접근하여 데이터를 가져온다. 이때, DB에서 가져온 데이터를 redis에 저장을 한다. 만약 똑같은 요청이 더 온다면 DB에 접근할 필요 없이 redis에서 데이터를 가져갈 수가 있다. DB에 접근을 하지 않는 것이니 필히 성능향상이 있는 것이다. 혹은, 처음부터 서버를 구동 시 DB로부터 데이터를 미리 redis로 옮겨 놓을 수도 있다.
이제 Springboot에 캐시를 적용해 보겠다.
우선 의존성을 추가해 주어야 한다.
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
이후 기본 설정 파일(yml로 작성)을 설정하자.
spring:
redis:
host: localhost
port: 6379
마지막으로 configuration 파일을 설정해야 한다.
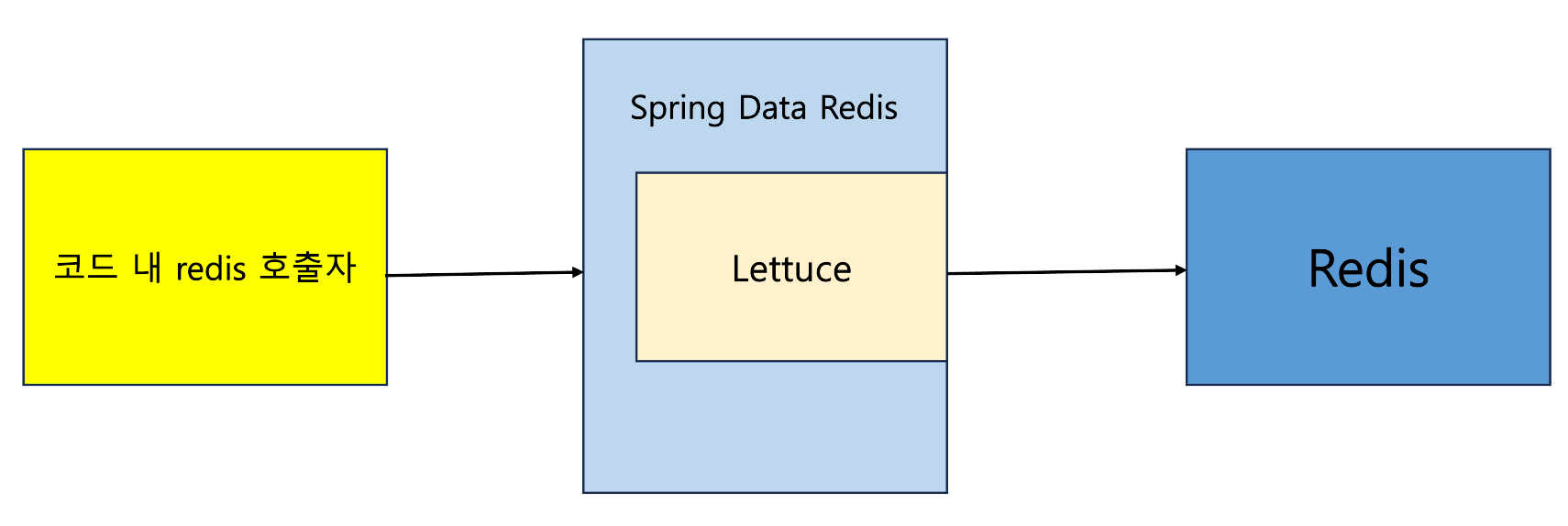
Springboot에서 Redis를 사용하기 위해서 자바의 클라이언트 라이브러리로 Jedis와 Lettuce가 있는데 이들을 통해 Redis를 연결하도록 설정을 하고 Bean으로 등록을 해야 한다. Lettuce는 위의 의존성만 추가하면 바로 사용할 수 있지만 Jedis는 별도의 의존성을 설정해야 한다. Lettuce이 성능이 더 좋다고 하여 가장 많이 사용된다고 하는데 여기를 참고해 보길 바란다.
Spring Data Redis는 RedisTemplate 이라는 Redis 조작을 위한 추상 레이어를 제공한다. 그렇기에 이를 Bean으로 등록하여 실제 코드에서 RedisTemplate을 의존성 주입하여 Redis를 조작할 수가 있다.
Spring boot 2.0부터는 RedisTemplate와 StringTemplate이 자동생성 되어서 따로 빈에 등록하지 않아도 된다고 한다.
하지만, Bean으로 등록을 할 때 세부적인 사항들을 더 자세히 작성할 수가 있기 때문에 등록하여 사용하는 것이 좋다.
우선 따로 Configuration을 등록하지 않고 진행해 보겠다.
@Autowired
RedisTemplate<String, String> redisTemplate;
public String findUserDetails(String userId) {
ValueOperations<String, String> ops = redisTemplate.opsForValue();
// redis에서 key에 해당하는 value를 찾음.
String cachedData = ops.get("userDetails::" + userId);
if (cachedData != null) {
System.out.println("redis에서 기록된 정보를 빼옴");
return cachedData;
}
// redis에 없을 경우 DB로부터 데이터를 가져와서 등록
String DBData = userRepository.findById(userId);
ops.set("userDetails::" + userId, DBData, 20, TimeUnit.SECONDS);
System.out.println("데이터베이스에서 기록된 정보를 빼옴");
return DBData;
}
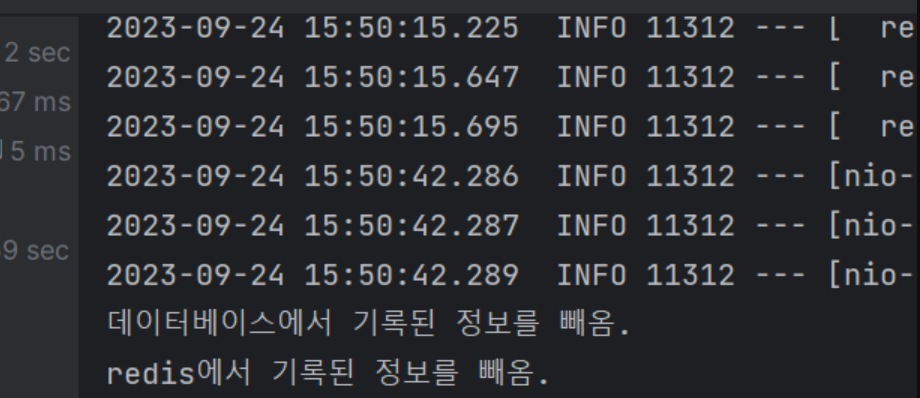
위에 코드를 보면 알 수 있듯이 첫 접근할 때에는 redisTemplate.opsForValue().get()을 실행하여 데이터를 가져오려 하지만 Redis 안에는 key에 해당하는 없을 것이다. 그래서 userRepository.findById()를 통해 DB에 접근하여 데이터를 가져온다. 하지만 redisTemplate.opsForValue().set()을 통해 redis에 저장을 해놓기에 다음 접근 때에는 redisTemplate.opsForValue().get()을 실행할 때 데이터가 정상적으로 넘어와서 DB에 접근을 하지 않고 return을 할 것이다. 아래는 실행 화면이다.
그렇다면 get()과 set()은 각각 어떤 값을 넣는 것일까?
Redis는 데이터를 key-value 형태로 String, Lists, Sets, Hashes, SortedSets, Bitmpas, HyperLogLogs 등 다양한 자료구조를 제공한다. redisTemplate.opsForValue()은 String의 형태로 데이터를 다룰 때 사용하는 것이라는 것이다. opsForValue 뿐만 아니라 자료구조 형태에 따라 다른 인터페이스들이 있으며 아래와 같다.
- opsForValue(String)
- opsForList(List)
- opsForSet(Set)
- opsForZset(SortedSet)
- opsForHash(Hash)
ops 인터페이스 별로 get() 또한 각각 파라미터가 다르며 위에서 사용한 것은 key 값을 넣었을 시 key 해당하는 String value 값을 리턴하는 것이다. 만약 key에 해당하는 value가 없다면 null을 리턴할 것이고, 있다면 null이 아니기에 바로 return하여 DB를 접근하지 않는다.
null일 경우에는 DB로부터 데이터를 가져와서 set()을 통해 Redis에 저장하였는데, set()의 첫번째 매개변수는 Key, 두 번째 매개변수는 value, 3번째 매개변수는 시간의 크기, 4번째 매개변수는 시간의 단위를 의미한다. 물론 여러 메서드로 오버로딩이 되어있기 때문에 꼭 위 방법만 고수하지 않아도 된다.
위 방식을 다시한번 정리하면 서버 요청 시 Redis를 접근하고 데이터가 있다면 이를 리턴, 없다면 DB에 접근하여 데이터를 조회하고 이를 Redis에 저장하고 리턴하는 방식이다.
하지만 코드를 일일이 치기가 귀찮지 않나? 생각할 수 있다. 우리가 중점으로 두는 메인 로직 외 로직인 캐시 로직을 자세히 작성하는 것은 효율적이지가 않다. 캐시와 관련된 로직 즉, 메인 로직 외의 관심사는 따로 구현을 해 두는 방식을 기억하는가? 바로 AOP이다.
놀랍게도 AOP 방식으로 어노테이션을 붙이는 것만으로도 캐시관련된 내용을 수행할 수가 있다..!
한번 어노테이션에 대해 봐보자.
2. 어노테이션을 통한 cache 적용
어노테이션으로는 @Cacheable, @CachePut, @CacheEvict 3가지가 있다.
@Cacheable는 캐시에 데이터가 있으면 메서드 로직을 실행하지 않고 캐시로부터 데이터를 조회하여 반환한다. 만약 캐시에 데이터가 없다면 메서드 내부의 로직을 실행하고 캐시에 데이터를 저장한 후 반환한다. 데이터를 조회 시 사용되며 위에서 구현한 방식이다.
@CachePut는 무조건 메서드 내부의 로직을 실행하고 캐시에 데이터를 저장한 후 반환한다. 데이터를 갱신할 때 사용된다.
@CacheEvict는 키값에 해당하는 데이터를 삭제한다.
한번 위에서 작성한 조회 코드에 어노테이션을 적용해 보자!
@Cacheable(key = "#userId", value = "userDetails")
public String findUserDetails(String userId) {
// DB로부터 데이터를 조회
String DBData = userRepository.findById(userId);
System.out.println("데이터베이스에서 기록된 정보를 빼옴");
return DBData;
}
끝났다..! 너무 짧아서 놀랄 수도 있는데, 어노테이션을 적용함으로써 Redis와 관련된 부분은 Service 내부에 작성할 필요는 없다.
어노테이션을 보면 key와 value가 있다. 이는 Redis에 userDetails::{userId}라는 이름의 key로 데이터를 조회, 저장한다는 것이다. key로 Redis를 조회하여 만약 데이터가 있으면 메서드의 반환타입(여기서는 String)으로 반환을 하고, 없다면 내부 로직을 수행한 후, Redis 내에 해당되는 key값으로 저장한다. 즉, 캐시에 데이터가 있다면, DB 접근을 하지 않고 바로 반환하고, 없다면 DB 접근을 한 후 반환하는 것이다.
이렇게 어노테이션을 통해 복잡한 코드가 단순화되었다. 어노테이션을 적용함으로써 관심사의 분리를 효과적으로 이뤄냈고 Service 내부에서는 오직 메인 로직만을 집중할 수가 있기에 많이 선호되는 방식이라고 한다.
하지만 무조건 반환되는 타입으로만 Redis에 저장이 되므로, 반환하는 데이터가 아닌 데이터를 Redis에 저장할 때에는 직접 RedisTemplate를 통해 구현한다고 한다.
하지만, 위 코드에서는 문제가 하나 있다. 바로 TTL 즉, Redis에 얼마동안 데이터가 보존되는지 정해지지 않았다.
이를 위해서는 Cache 어노테이션에 대한 구체적인 설정을 하는 Config 파일을 작성해야 한다.
아래의 코드를 봐보자.
@Configuration
public class RedisConfig {
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory) {
RedisCacheConfiguration configuration = RedisCacheConfiguration.defaultCacheConfig()
.disableCachingNullValues()
.entryTtl(Duration.ofSeconds(30))
.computePrefixWith(CacheKeyPrefix.simple())
.serializeKeysWith(
RedisSerializationContext.SerializationPair.fromSerializer(
new StringRedisSerializer())
)
.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(
new GenericJackson2JsonRedisSerializer())
);
return RedisCacheManager
.RedisCacheManagerBuilder
.fromConnectionFactory(connectionFactory)
.cacheDefaults(configuration)
.build();
}
}
세부적인 설정을 한 RedisCachManager을 @Bean으로 등록을 하였다.
RedisConnectionFactory는 Lettuce 라이브러리를 사용하여 연결하는 것이다.
RedosCacheConfiguration 객체를 생성할 때 주로 확인할 부분은 entryTtl(), serializeKeysWith(), serializeValuesWith()이다.
entlryTtl()은 위에서 문제가 되었던 TTL이다.
serializeKeysWith()와 serializeValuesWith()는 각각 Key와 Value를 직렬화, 역직렬화할 때, 어떤 방식으로 진행할지를 정하는 것이다. 자바에서 객체를 Redis에 저장할 때에는 Redis에서의 자료구조는 형식을 따라야 하기에 Redis의 자료구조 형식으로 변환을 해주어야 한다. 그렇기에 위 두 메서드가 필요한 것이고, StringRedisSerializer()는 String 형태로, GenericJackson2JsonRedisSerializer()는 어떤 식으로 구현된 dto든지 json 형태의 String으로 직렬화해주는 메서드이다.
이렇게 설정을 해준 후, 다시 어노테이션이 적용된 Service 메서드 부분으로 가보자.
@Cacheable(key = "#userId", value = "userDetails", cacheManager = "cacheManager")
public String findUserDetails(String userId) {
// DB로부터 데이터를 조회
String DBData = userRepository.findById(userId);
System.out.println("데이터베이스에서 기록된 정보를 빼옴");
return DBData;
}
어노테이션에 cacheManager란 값을 추가하였다. 이렇게 하면 config 파일 내에 설정해 둔 cacheManager를 지정하여, 설정된 값들을 그대로 따르게 된다.
수정을 위한 @CachePut 또한 똑같이 메서드에 적용을 할 수 있고, 메서드 내부의 로직을 무조건 실행한 후 캐시에 데이터를 저장한다는 점에서 차이가 있다.
@Cacheput(key = "#userId", value = "userDetails", cacheManager = "cacheManager")
@CacheEvict도 똑같이 작성하고, 메서드 내부의 로직을 무조건 실행하고 캐시 내 데이터를 제거한다.
@CacheEvict(key = "#userId", value = "userDetails", cacheManager = "cacheManager")
* 참고로 맨 처음 사용한 RedicTeplate도 config 파일 내에서 bean으로 작성하여 내부 세부적인 설정을 추가할 수 있다.
@Configuration
public class RedisCashConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<String, String> redisTemplate = new RedisTemplate<>();
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setConnectionFactory(connectionFactory);
return redisTemplate;
}
}
RedisConnectionFactory로 Lettuce를 통해 연결을 할 수 있으며 일반적인 Map의 형태처럼 <String, Object>으로 생성이 된다. 이는 String 타입의 Key와 Object 타입의 Value로 구성되는 것이다.
setKeySerializer과 setValueSerializer은 key와 value를 각각 어떻게 직렬화하여 Redis에 저장할 것인지를 나타내고 있다.
결론
간단하게 Springboot에 Redis를 적용할 수가 있었다. RedisTemplate을 직접 사용할 수도 있고 어노테이션을 달아서 적용할 수 있는데, 일반적으로 어노테이션을 적용하는 방식이 더 선호된다고 한다.
어노테이션을 달아서 '캐시 기능'이라는 관심사를 분리하여 메인 로직만을 집중하여 개발할 수 있고, 가독성 면에서도 우수하기 때문이다.
하지만 반환되는 데이터를 캐시에 저장한다는 한계가 있어서 메인 로직 실행 도중에 반환 데이터가 아닌 다른 부분 데이터를 캐시에 저장할 때는 RedisTemplate를 직접 사용할 수밖에 없을 것이다.
다만, @CacheEvict 같은 경우 캐시 내에 key 값에 해당하는 데이터를 제거하는 것이므로, 반환되는 데이터에 제한받지 않는다.
한 가지 더 추가적으로 언급을 하자면, 위에서 사용한 GenericJackson2JsonRedisSerializer()을 통한 직렬화 방식은 문제가 하나 있다. 이에 대해서는 https://khdscor.tistory.com/100를 참고하 바란다.
* 궁금하거나 잘못된 부분에 대해서 댓글로 달아주시면 감사하겠습니다...!
참고
https://bcp0109.tistory.com/386
Spring Boot 에서 Redis Cache 사용하기
Overview 베이스 코드로 Spring Boot Cache 적용에 있던 코드들을 재활용할 예정이라 앞의 글을 먼저 읽어보는걸 추천합니다. 단순하게 Redis Cache 설정만 알고 싶다면 상관 없습니다. 코드를 직접 실행해
bcp0109.tistory.com
https://www.woolog.dev/backend/spring-boot/spring-boot-redis-cache-simple/
SpringBoot에서 Redis 캐시를 사용하기
목차 사용 할 Redis 간단 설명 프로젝트 구조 준비 할 것 Database SpringBoot SpringBoot와 Redis를 사용하여 프로젝트 작성 SpringBoot…
www.woolog.dev
https://prodo-developer.tistory.com/157
[SPRING] Spring Redis Cache
Redis 란? Key-Value 형태를 띄고 있는 In Memory 기반의 NoSQL DBMS이다. 최근에 실무에서도 50만건의 데이터를 추출하기 위해 Redis를 사용할 일이 있었다. 기존 RDMS의 조회 시 7분 40초에서 레디시 캐시 등
prodo-developer.tistory.com
https://velog.io/@akfls221/RedisDocker를-통한-Cache전략-알아보기
Redis(Docker)를 통한 Cache전략 알아보기
Redis를 통한 Cache전략을 코드로 알아보자
velog.io
https://helloworld.kurly.com/blog/redis-fight-part-1/
DevOps 엔지니어의 Redis Test 분투기 - Part 1
Redis 테스트를 진행했습니다.
helloworld.kurly.com
https://docs.spring.io/spring-data/redis/docs/current/reference/html/#redis:serializer
Spring Data Redis
Some commands (such as SINTER and SUNION) can only be processed on the server side when all involved keys map to the same slot. Otherwise, computation has to be done on client side. Therefore, it is useful to pin keyspaces to a single slot, which lets make
docs.spring.io
[REDIS] 📚 캐시(Cache) 설계 전략 지침 💯 총정리
Redis - 캐시(Cache) 전략 캐싱 전략은 웹 서비스 환경에서 시스템 성능 향상을 기대할 수 있는 중요한 기술이다. 일반적으로 캐시(cache)는 메모리(RAM)를 사용하기 때문에 데이터베이스 보다 훨씬 빠
inpa.tistory.com
'redis' 카테고리의 다른 글
| Springboot With Redis: 데이터 Dto 저장, 조회 시 직렬화 문제 및 Enum을 활용한 갱신 (1) | 2023.10.14 |
|---|---|
| Redis: In-Memory DB로서 뛰어난 성능 (0) | 2023.09.24 |

