스프링 및 JPA 프로젝트를 진행하면서 데이터베이스에 접근해야 할 일은 많을 것이다. 하지만 일반적으로 데이터베이스에 접근할 때의 시간 비용은 애필리케이션 서버 내부 메모리에 접근하는 시간 비용보다 수만에서 수십만 배 이상 비싸다고 한다. 즉, 데이터베이스안에 있는 데이터를 캐싱하면 성능을 획기적으로 향상시킬 수 있다.
여기서 캐싱이란 운영체제를 공부하다보면 자주 보았을 단어일 것이다.
캐싱(Caching)은 캐시(Cache)라고 하는 더 빠른 메모리 영역으로 데이터를 가져와서 접근하는 방식을 말한다. 예를 들어 속도가 느린 하드디스크의 데이터를 메모리로 가지고 와서 메모리 상에서 작업을 수행하는 것을 '데이터를 메모리에 캐싱한다' 라고 한다. 그리고 메모리 상에 있는 데이터에 연산을 수행하기 위해 더 빠른 메모리인 CPU 메모리 캐시로 데이터를 가지고 와서 연산을 수행하는 것도 캐싱이라고 한다.
여기서 어떤 데이터를 캐싱할지를 선택하는 기준은 지역성(Locality)에 따른다. 지역성은 공간 지역성과 시간 지역성이 있는데 공간 지역성은 최근에 접근했던 데이터의 주변에 있는 데이터가 다시 접근될 확률이 높은 것을 의미한다. 시간 지역성은 최근에 접근했던 데이터가 가까운 시간내에 다시 접근될 확률이 높은 것을 의미한다.
캐싱의 목표는 이러한 특성을 통해 자주 접근될 데이터를 더 빠른 메모리, 비용이 덜 소모되는 곳에 가지고 와서 성능을 최적화하는 것이다.
웹서버를 담당하는 엔진엑스에서도 캐시 기능이 사용되고 있고 여러 곳에 쓰이고 있으며 물론 JPA에서도 캐시기능이 사용되고 있다.
JPA기능을 사용하면서 데이터베이스에 접근하다보면 누구나 캐싱기법을 사용하게 된다. 바로 영속성 컨텍스트를 통해서이다. 영속성 컨테스트 내부에는 엔티티를 보관하는 저장소가 있는데 이를 1차 캐시라고 한다. 데이터베이스에 접근하여 가져온 데이터는 영속성 컨텍스트안에 인티티 저장소에 보관되어 트랜잭션이이 실행되는 동안 유지되게 된다. 즉 캐싱기능이 사용되는 것이다. 혹은 OSIV(OpenServiceInView) 기능으로 영속성 컨텍스트의 수명을 확장시켜 뷰까지 지속된다면 뷰가 끝날때까지 캐싱기능이 동작한다. 하지만 1차 캐시는 결국 영속성 컨텍스트가 있을 때에만 유효하다. 특정한 기능을 수행하는 동안에만 유효하다고 할 수있다. 이는 애플리케이션 전체로 보면 데이터베이스 접근 횟수를 획기적으로 줄이지는 못한다.
예를 들어, 특정한 데이터를 조회하는 기능을 사용자가 여러번 실행한다고 하자. 한 번의 조회가 진행되는 동안에는 1차 캐시는 유효할 것이다. 하지만 이어서 연속적으로 조회를 한다면 1차 캐시를 제대로 활용하지 못하고 계속해서 데이터베이스에 접근을 시도할 것이다.
하이버네이트를 포함한 대부분의 JPA 구현체들은 애플리케이션 범위의 캐시를 지원하는데 이것을 공유 캐시 또는 2차 캐시라고 한다. 이런 2차 캐시를 이용하면 애플리케이션 조회 성능을 향상시킬 수 있다. 즉, 위의 예시에서 처음에 데이터를 가져올 때 빼고는 데이터베이스에 접근을 하지 않을 수 있다는 것이다.
2차 캐시를 적용하기 전에는 1차 캐시가 있는 영속성 컨텍스트에서 데이터 베이스를 조회하여 데이터를 찾았다.
2차 캐시가 있을 때는 영속성 커텍스트가 2차 캐시를 먼저 확인하고 2차 캐시에 없을 시 데이터 베이스를 조회하고 데이터를 2차 캐시에 보관한다. 즉, 2차 캐시에 필요한 데이터를 놔두면 데이터 베이스 접근을 확 줄일 수 있는 것이다.
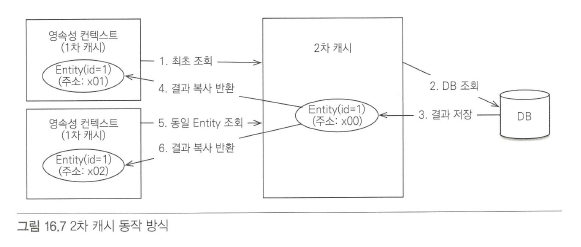
1차 캐시가 영속성 컨텍스트 범위의 캐시라면 2차 캐시는 애플리케이션 범위의 캐시다. 따라서 애플리케이션을 종료할 때까지 캐시가 유지된다.
2차 캐시는 동시성을 극대화하기 위해 캐시한 객체를 직접 변환하지 않고 복사본을 만들어서 반환한다. 만약 캐시한 객체를 그대로 반환하면 여러 곳에서 같은 객체를 동시에 수정하는 문제가 발생할 수 있다.
이를 해결하기 위해서는 락을 걸어야 하는데 이렇게 하면 동시성이 떨어질 수 있다. 락에 비하면 객체를 복사하는 비용은 아주 저렴하다.
2차 캐시는 다음과 같은 특징이 있다.
- 2차 캐시는 영속성 유닛 범위의 캐시이다.
- 2차 캐시는 조회한 객체를 그대로 반환하지 않고 복사본을 반환한다.
- 영속성 컨텍스트가 다르면 객체를 가져올 때는 복사한 객체이므로 객체간의 동일성을 보장하지 않는다.
참고
자바 ORM 표준 JPA 프로그래밍 - 김영한
https://m.blog.naver.com/complusblog/221204759836
캐싱(Caching)과 버퍼링(Buffering) 그리고 스풀링(Spooling)
운영체제 혹은 시스템 소프트웨어를 다루다보면 캐싱(Caching), 버퍼링(Buffering), 스풀링(Spooling)에...
blog.naver.com
4. JPA Cache 적용하기
서론 이번 포스팅에서는 JPA에 Cache 적용방법에 대해서 다루어보겠습니다. 먼저 Cache 선정 기준 및 패턴에 대한 소개 및 적용 방법을 설명합니다. Cache로는 Ehcache3을 적용하며, Spring Actuator를 통해
cla9.tistory.com
'JPA' 카테고리의 다른 글
| 스프링부트 With JPA - mysql 연동 (0) | 2021.12.06 |
|---|---|
| JPA - 읽기 전용으로 데이터를 조회하여 성능 향상(메모리, 속도) (0) | 2021.09.18 |
| JPA - 트랜잭션과 락 (0) | 2021.09.02 |
| JPA 두번 이상의 left join fetch가 필요할 때 해결 방법(MultipleBagFetchException 문제 해결) (0) | 2021.08.23 |
| JPA 특정 엔티티 삭제시 연관된 엔티티도 함께 삭제하기 (0) | 2021.08.15 |

