들어가기
이 글은 채팅 프로그램 구현 후, 다중 서버일 경우 발생할 수 있는 문제를 해결하기 위해 카프카(kafka)를 적용하는 과정을 담은 글로, https://khdscor.tistory.com/122에서 구현한 채팅 프로젝트로부터 코드가 이어진다.
Spring boot with React: STOMP를 통해 채팅 시스템을 구현해보자(With Mysql, MongoDB)(2)
들어가기 이 글은 https://khdscor.tistory.com/121에서 이어진다. 여기선 의존성, Config 파일 등 세부적인 파일을 다루지 않고 바로 비즈니스 로직을 작성한 과정을 담았다. 이에 대해 궁금한 것은 이전
khdscor.tistory.com
이전에 토이 프로젝트로 STOMP를 통해 Spring boot, React를 사용하여 채팅 프로그램을 구현하였다. 사용자가 페이지 접근 시 Spring boot 서버로 웹소켓을 열고 유지하여 메시지를 주고받을 수 있게 하였다.
하지만 만약 다중 서버일 경우, 문제가 생긴다.
아래의 예시를 봐보자.
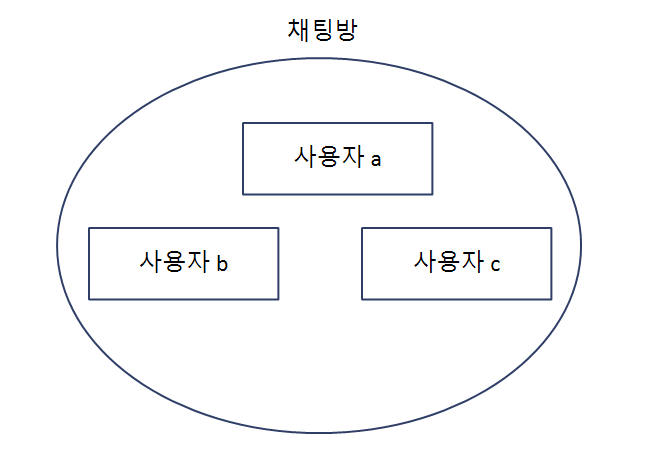
채팅방에 사용자 a, b, c가 있다.
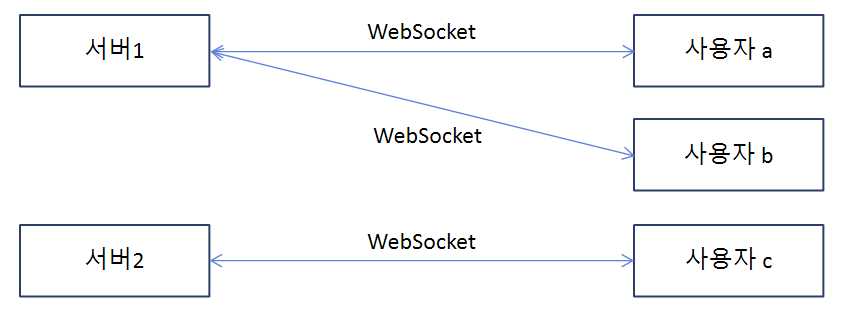
서버 1, 2를 이용하고 있고, 채팅방에 들어갈 시 채팅 기능을 위해 사용자 a, b는 서버 1과 웹소켓 연결을, 사용자 c는 서버 2와 웹소켓 연결을 하였다.
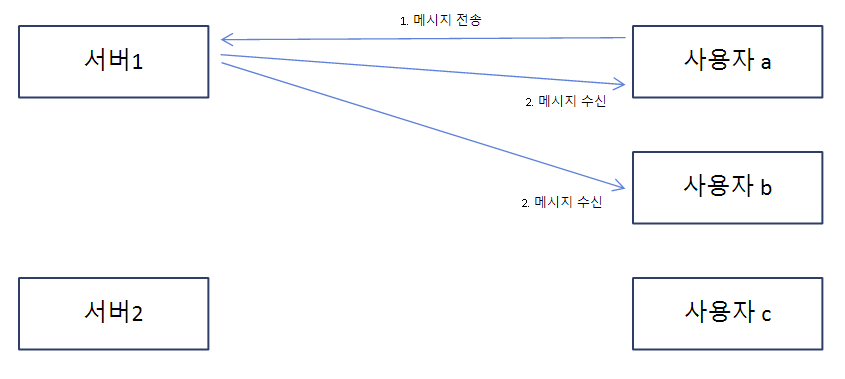
사용자 a가 메시지를 전송하면, 서버 1과 웹소켓 연결이 되어있는 사용자 a, b로만 메시지가 수신이 되고 사용자 c는 메시지를 수신하지 못한다. 같은 채팅방인데도 말이다. 그 이유는 사용자 c가 서버 1이 아닌 서버 2와 웹소켓 연결을 하고 있기 때문이다.
이를 해결하기 위해 메시지 스트리밍 플랫폼인 카프카(Kafka)를 사용할 것이다.
아래의 그림을 봐보자.
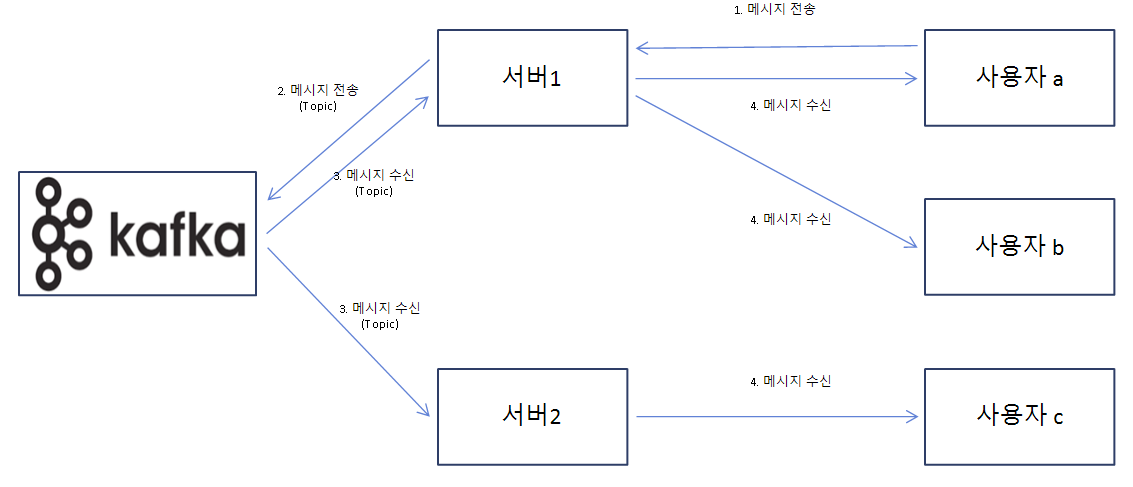
사용자 a가 메시지를 전송하면 서버 1은 Producer로서 특정 '토픽'에 맞게 카프카 브로커로 메시지를 전송하고, 해당 메시지는 해당 토픽을 구독하고 있는 Concumser들 즉, 서버 1과 서버 2에서 수신하게 된다. 수신된 메시지는 각 서버와 웹소켓 연결되어 있는 사용자들에게 전달되어 결국, 사용자 a, b, c 모두 메시지를 확인할 수 있게 된다.
정리하면 다중 서버 환경에서 Stomp를 기반으로 한 웹소켓 연결을 통해, 클라이언트가 어느 서버에 접속하든 상관없이 일관된 실시간 메시징을 보장하기 위해 카프카를 메시지 브로커(중계)로 활용한다는 것이다.
이 글에서는 Spring boot와 함께 카프카를 통해 문제를 해결하는 과정을 단계별로 확인할 것이다.
카프카에 대한 기본적인 내용은 https://khdscor.tistory.com/107를 참고하길 바란다. 또한 카프카와 Spring boot 연동 부분도 빠르게 진행될 것이기에 이에 대한 설명은 https://khdscor.tistory.com/108를 참고하길 바란다.
목차는 아래와 같다.(클릭 시 이동)
4. 트러블 슈팅 : 동적으로 카프카 토픽 구독/해제(웹소켓 연결된 사용자 수에 따라 진행)
본론
우선 카프카를 실행해야하는데, 나는 도커 이미지를 도커 컴포즈를 통해 실행하였다. 실행 방법은 아래의 글을 참고하길 바란다.(브로커 3개와 주키퍼 1개를 운용)
[Apache Kafka] docker-compose를 통한 kafka 구축 과 크롤링 데이터 전송
EC2 인스턴스에 kafka를 직접 설치하는 방식이 아닌 docker-compose를 통해 다중 브로커를 만들고 실행해보자kafka 브로커 3개로 구성된 클러스터 생성포트는 9092, 9093, 9094로 설정 (ec2 인스턴스 보안설정
velog.io
1. 사용자가 WebSocket을 통한 메시지 전송
우선 첫 번째 순서로 사용자가 메시지를 전송하였을 때이다. 목표는 서버에 상관없이 채팅방에 들어있는 모든 사용자가 메시지를 수신하는 것이다. 아래와 같이 @MessageMapping 어노테이션을 통해 사용자가 메시지 전송 시 해당 메서드를 실행하도록 하였다.
private final ChatService chatService;
private final KafkaProducerService kafkaProducerService;
//메세지 송신 및 수신
@MessageMapping("/message")
public Mono<ResponseEntity<Void>> receiveMessage(@RequestBody RequestMessageDto chat) {
// chatService에 대한 내용은 이전 내용을 참고하길 바란다.
return chatService.saveChatMessage(chat).flatMap(message -> {
// 메시지를 해당 채팅방 구독자들에게 전송
kafkaProducerService.send(ResponseMessageDto.of(message));
return Mono.just(ResponseEntity.ok().build());
});
}
였다. chatService.saveChatMessage()를 실행하여 비동기 방식으로 메시지를 MonogoDB에 저장하였고(자세한 내용은 글 상단에 기재한 프로젝트 이전 글을 참고하길 바란다), kafkaProducerService.send()를 통해 Producer 역할로서 카프카 브로커에 메시지를 보내도록 하였다. 보낸 메시지는 Consumer에게 전달되어 채탕방에 참여 중인 모든 사용자에게 전달될 것이다.
이제 send() 내부의 코드를 살펴보자.
2. Kafka Producer로서 메시지 전송
본격적으로 Service를 살펴보기 전에 ProducerConfig 파일을 살펴보자.
@Configuration
public class KafkaProducerConfig {
private static final String BOOTSTRAP_SERVER = "localhost:9092, localhost:9093, localhost:9094";
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVER);
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 파티셔닝 전략 설정
configProps.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, RoundRobinPartitioner.class.getName());
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
BOOTSTRAP_SERVER는 열려있는 카프카 브로커의 주소로 현재 3개를 운용하고 있다.
주로 확인할 점은 주석으로 '파티셔닝 전략 설정'이라고 적어놓은 부분이다. 코드를 보면 'RoundRobinPartitioner'로 설정한 것을 볼 수 있다. 처음에 위 설정을 하지 않으면 카프카 버전 2.4 이후부터는 파티션 메시지 분배 전략이 기본으로 스티키 방식으로 적용되기 때문에, 나는 라운드로빈 방식으로 설정하였다.
메시지 분배 전략에 대한 자세한 내용은 https://khdscor.tistory.com/126를 참고하길 바란다.
Kafka - Producer 메시지 분배 전략(파티셔닝 전략)과 배치(feat. 하나의 파티션으로만 메시지가 전송
들어가기 Spring boot와 Kafka를 같이 사용하는 토이 프로젝트를 진행 중이었다.Kafka ui 툴을 통해서 메시지가 잘 전송이 되나~ 확인하려고 했는데 내 눈을 의심하였다...어째서 파티션 하나로만 메
khdscor.tistory.com
이제 주된 로직이 구성되어 있는 ProducerService를 봐보자.
@Service
@RequiredArgsConstructor
public class KafkaProducerService {
private static final String TOPIC_NAME = "chatting";
private final KafkaTemplate<String, String> kafkaTemplate;
private final ObjectMapper objectMapper = new ObjectMapper();
public void send(ResponseMessageDto message){
try {
String toJson = objectMapper.writeValueAsString(message);
kafkaTemplate.send(TOPIC_NAME, toJson);
} catch (Exception e) {
throw new RuntimeException("예외 발생 : " + e.getMessage());
}
}
}
토픽 이름은 'chatting'로 설정하였다. ObjectMapper를 통해 dto를 json형식의 String으로 변환하여 send() 메서드를 통해 브로커로 전송하였다. Producer 관련 코드는 이것으로 끝이고 이제 전송된 메시지를 수신하는 Consumer 코드를 살펴보자.
3. Kafka Consumer로서 메시지 수신
Producer와 마찬가지로 Config 파일을 먼저 살펴보자.
@EnableKafka
@Configuration
public class KafkaConsumerConfig {
private static final String BOOTSTRAP_SERVER = "localhost:9092, localhost:9093, localhost:9094";
//서버 실행 시 환경 변수로 서버마다 다른 그룹 아이디를 가지도록 설정
private final static String GROUP_ID = System.getenv("GROUP_ID");
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVER);
configProps.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(configProps);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}
BOOTSTRAP_SERVER는 Producer와 동일하게 3개의 브로커를 지정하였다.
주로 살펴볼 점은 그룹 아이디를 환경변수로 가져온 점이다. 그룹 아이디를 동일하게 맞춘 서버들끼리는 오직 하나의 서버로만 메시지가 전송되기 된다. 그렇기에 모든 서버에 메시지를 전송하기 위해서는 그룹 아이디를 모두 다르게 설정해야 한다.
서버는 인텔리제이로 실행하였기에, 아래와 같이 포트별로 다른 환경 변수를 설정해 주었다.
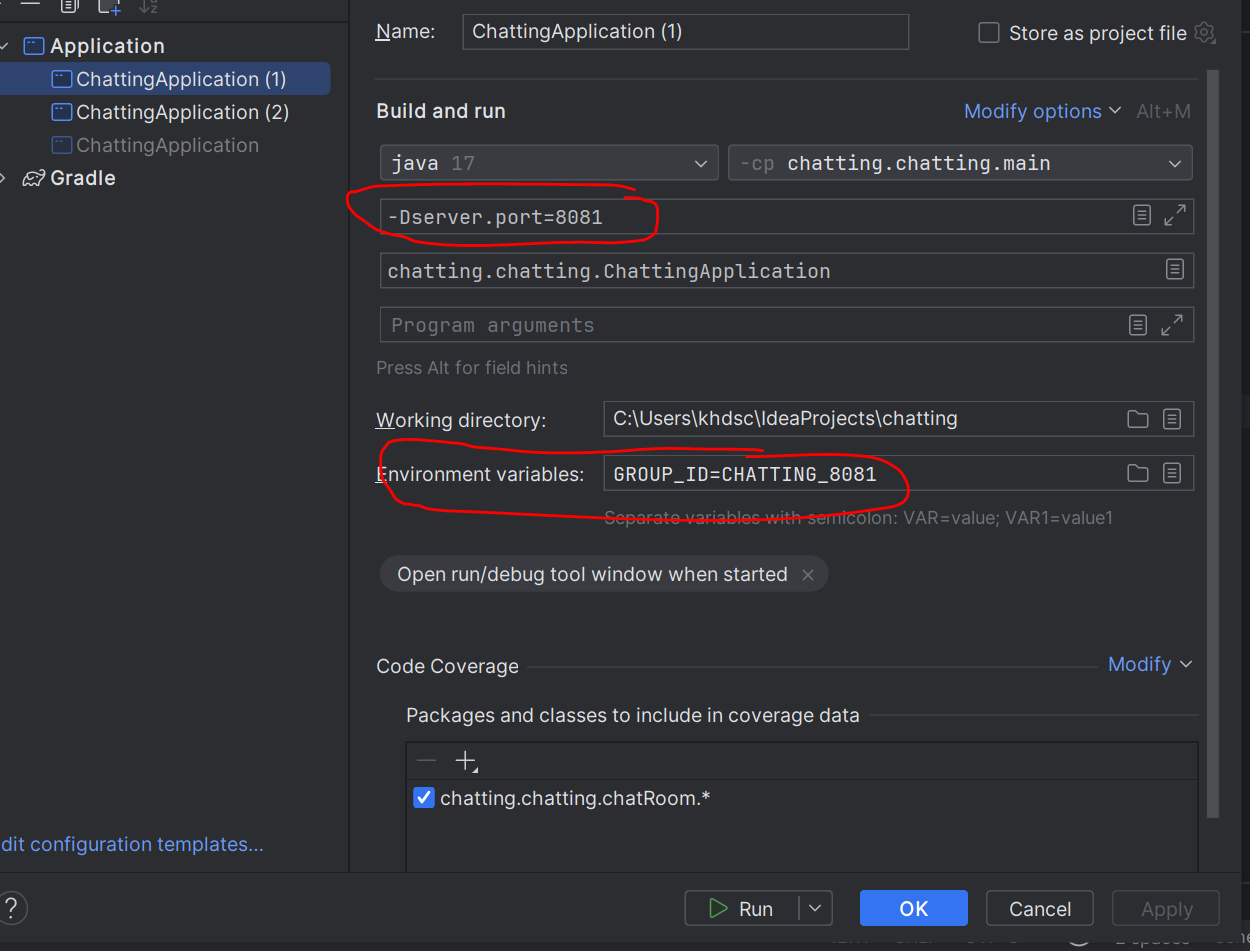
이제 ConsumerService를 살펴보자.
@Component
@RequiredArgsConstructor
public class KafkaConsumerService {
private static final String TOPIC_NAME = "chatting";
private final SimpMessageSendingOperations template;
ObjectMapper objectMapper = new ObjectMapper();
@KafkaListener(topics = TOPIC_NAME)
public void listenMessage(String jsonMessage) {
try {
ResponseMessageDto message = objectMapper.readValue(jsonMessage,
ResponseMessageDto.class);
// 웹 소켓 연결하고 있는 클라이언트들에게 메시지 전송
template.convertAndSend("/sub/chatroom/" + message.getRoomId(), message);
} catch (Exception e) {
throw new RuntimeException("예외 발생 : " + e.getMessage());
}
}
}
ProducerService에서와 마찬가지로 토픽 이름은 동일하게 'chatting'으로 설정하였다. @KafkaListener 어노테이션을 통해 설정한 토픽 이름으로 카프카 브로커로부터 메시지를 수신한 후 ObjectMapper를 통해 json 형식의 String 값을 dto로 변환하였다.
마지막으로 convertAndSend() 메서드를 통해 해당 서버와 웹소켓 연결되어 있는 모든 사용자에게 메시지를 전송할 수 있다.
이렇게 하면 해당 토픽을 구독하고 있는 모든 서버가 사용자에게 메시지를 전송하게 되어, 서로 다른 서버와 웹소켓 연결을 하고 있는 모든 사용자에게 메시지를 전송할 수 있게 된다. 아래는 간단한 시연 영상이다.
4. 트러블 슈팅 : 동적으로 카프카 토픽 구독/해제(웹소켓 연결 된 사용자 수에 따라 진행)
현재 상황에서는 문제가 하나 있다. 사용자들의 웹소켓 연결 여부와 상관없이 Spring boot 서버를 실행하자마자 @KafkaListener를 통해 토픽을 구독하는 것이다. 결국 아무도 웹 소켓이 연결되어 있지 않더라도 Producer가 메시지를 보내면 해당 메시지를 수신하는 것이다. 이는 웹소켓 연결/해제에 상관없이 Producer가 메시지를 보내면 Consumer의 send() 메서드가 계속해서 실행되는 것이다.
그렇다고 해도 에러는 발생하지 않는다. 웹소켓 연결이 되어있는 사용자가 없을 뿐이지 웹소켓 메시지 전송은 이상 없이 이루어지기 때문이다.
사실 이는 프로그램이 어떻게 사용되는지에 따라 고민할 문제이다. 만약 채팅이 주된 기능으로 사용되며 많은 사람들이 끊임없이 채팅을 사용하는 프로그램일 경우 서버 실행 시 바로 구독을 한 상태를 유지하는 것이 구독 연결, 해제를 반복하는 것보다 더 좋을 수 있다.
하지만 채팅이 주가 아니거나 적은 사람이 채팅을 유지하기에 사용자들의 웹소켓 연결이 적은 경우에는 불필요한 리소스가 지속적으로 사용되는 방지하기 위해 웹소켓 연결/해제 시마다 구독을 설정/해제하는 것이 더 좋을 수 있다.
지금은 후자의 경우로 생각하며 선택적으로 구독을 하도록 코드를 수정하겠다.
나는 이를 해결하기 위해 웹소켓을 연결 시 카프카 토픽 구독하고, 웹소켓 연결 해제 시 토픽 구독을 해제하도록 생각을 하였다.
이를 위해선 두 가지 부분을 추가해야 한다.
첫 번째로 @KafkaListener로 특정 토픽을 구독하는 행위를 동적으로 조절하는 것이다. 구독을 시작하는 메서드와 구독을 종료하는 메서드를 구현해야 한다.
두 번째로 누군가 웹소켓 연결/해제 시마다 웹소켓에 연결한 사용자가 있는지 확인하고, 카프카 구독/해제하는 메서드를 실행해야 한다.
이 두 가지 기능을 추가 구현한다면 위에서 발생한 문제를 해결할 수 있다.
우선 첫 번째 부분부터 보겠다. 토픽을 구독하는 행위를 동적으로 조절해야 한다. 이를 위해 사용되는 것이 @KafkaListener 어노테이션의 옵션 중 'id'와 'autoStartup'이다. 아래는 이 옵션을 설정한 ConsumerService에 @KafkaListener 어노테이션을 단 메서드이다.
@Component
@RequiredArgsConstructor
public class KafkaConsumerService {
private static final String TOPIC_NAME = "chatting";
private final SimpMessageSendingOperations template;
private final KafkaListenerEndpointRegistry endpointRegistry;
ObjectMapper objectMapper = new ObjectMapper();
@KafkaListener(id = "dynamicListener", topics = TOPIC_NAME, autoStartup = "false")
public void listenMessage(String jsonMessage) {
try {
ResponseMessageDto message = objectMapper.readValue(jsonMessage,
ResponseMessageDto.class);
template.convertAndSend("/sub/chatroom/" + message.getRoomId(), message);
} catch (Exception e) {
throw new RuntimeException("예외 발생 : " + e.getMessage());
}
}
}
이전하고 크게 달라진 부분은 없다. 단순히 id 옵션과 autoStartup 옵션을 추가하였다.
autoStartup 옵션을 false로 설정하여 서버 실행 시 자동으로 카프카 토픽을 구독하지 않도록 하고, 설정한 id를 통해 메서드 실행 시 토픽 구독, 해제할 수 있도록 하였다.
아래는 구독을 하는 메서드와 구독을 해제하는 메서드이다.
public void startListening() {
endpointRegistry.getListenerContainer("dynamicListener").start();
System.out.println("startListening");
}
public void stopListening() {
endpointRegistry.getListenerContainer("dynamicListener").stop();
System.out.println("stopListening");
}
이렇게 첫 번째 부분을 구현하였다. 이제 두 번째 부분을 구현해야 한다. 우선 웹소켓에 연결된 사용자가 있는지 알아야 한다. 그렇기에 아래와 같이 사용자 수를 담는 객체를 구현하였다.
@Component
public class WebSocketTracker {
private AtomicInteger connectionCount = new AtomicInteger(0);
public void userConnected() {
connectionCount.incrementAndGet();
}
public void userDisconnected() {
connectionCount.decrementAndGet();
}
public boolean hasActiveConnections() {
return connectionCount.get() > 0;
}
}
그다음 사용자가 웹 소켓에 연결, 해제를 감지하고 메서드를 실행해야 한다. @EventListener와 SessionEvent 객체를 활용하여 누군가 웹소켓 연결 시 handleWebSocketConnectListener()를 실행하고 누군가 웹 소켓 종료 시 handleWebSocketDisconnectListener()를 실행하도록 구현하였다.
@Component
@RequiredArgsConstructor
public class WebSocketEventListener {
private final KafkaConsumerService kafkaConsumerService;
private final WebSocketTracker webSocketTracker;
@EventListener
public void handleWebSocketConnectListener(SessionConnectEvent event) {
// 웹소켓 연결 시 사용자가 아무도 없을 경우
if (!webSocketTracker.hasActiveConnections()) {
// 카프카 컨슈머로서 구독 시작
kafkaConsumerService.startListening();
}
// 사용자 추가
webSocketTracker.userConnected();
}
@EventListener
public void handleWebSocketDisconnectListener(SessionDisconnectEvent event) {
// 웹소켓 종료 시 사용자 제거
webSocketTracker.userDisconnected();
// 웹소켓 연결한 사용자가 아무도 없을 경우
if (!webSocketTracker.hasActiveConnections()) {
// 카프카 구독 종료
kafkaConsumerService.stopListening();
}
}
}
handleWebSocketConnectListener()를 실행하면 웹소켓에 연결한 사용자 유무를 확인하고 연결된 사용자가 아무도 없다면 카프카 컨슈머 구독 메서드를 실행한다. 그 후 웹소켓 연결한 사용자 수를 1 증가시킨다.
handleWebSocketDisconnectListener()를 실행하면 웹소켓 연결한 사용자 수를 1 감소시킨다. 그 후 웹소켓 연결한 사용자가 아무도 없다면 카프카 컨슈머 구독 종료 메서드를 실행한다.
이렇게 설정함으로써 웹소켓 연결, 종료 시마다 웹소켓에 연결된 사용자가 있는지 파악하고, 카프카 컨슈머로서 구독을 취사 선택할 수 있게 되었다.
결론
이렇게 카프카를 사용하여 다중 서버일 시 웹소켓을 통한 채팅 프로그램이 겪는 문제를 해결하였다. 여러 가지 기술이 적용되면서 각 기술 별 새로운 내용들을 많이 알게 되어 알차게 학습한 시간이었다.
또한 트러블 슈팅의 경우는 상황에 따라 성능상 좋을 수도, 좋지 않을 수도 있고 더 좋은 방식의 로직이 있을 수 있다. 이와 관련하여 다른 방식의 구현 방법에 대해 알고 있다면 댓글로 남겨주시면 감사하겠습니다..!
다음엔 스프링 배치와 스케줄링을 카프카와 연계하여 구현해 볼 것이다. 아무리 MongoDB를 사용하고 있다지만, 결국 채팅할 때마다 메시지를 저장하기 위해 DB를 접근하는 것은 사용자가 많을수록 비용이 많이들 것이다. 이를 위해 카프카 브로커에 저장된 메시지를 스케줄링 계획에 따라 한 번에 데이터베이스에 저장하는 과정을 밟아볼 것이다.
언제가 될진 모르겠지만, 다음 글에서 뵙겠습니다.
글을 읽으며 잘못된 부분이나 이해가 안 되는 부분에 대해서 댓글로 남겨주시면 감사하겠습니다..!!
참고
https://jessyt.tistory.com/151
Spring-Kafka Lifecycle
이번 글에서는 Spring-Kafka의 Lifecycle에 대해서 작성해보겠습니다. 목차 Lifecycle Lifecycle Management 주의사항 1. Lifecycle @KafkaListener는 Application Context 안에 Bean이 아닙니다. @KafkaListener는 KafkaListenerEndpointR
jessyt.tistory.com
https://hyeon9mak.github.io/web-socket-disconnection-detection/
web-socket 연결 끊김 감지하기
🐧 Summary 클라이언트A가 서버와 소켓 연결을 끊을 경우(Disconnect) 서버에 해당 소식을 전달하고, 소식을 접한 서버가 나머지 클라이언트들에게 클라이언트A의 연결이 끊겼음을(퇴장했음을) 알리
hyeon9mak.github.io
https://velog.io/@ytytyt0427/Apache-Kafka-docker-compose를-통한-kafka-구축-과-크롤링-데이터-전송
[Apache Kafka] docker-compose를 통한 kafka 구축 과 크롤링 데이터 전송
EC2 인스턴스에 kafka를 직접 설치하는 방식이 아닌 docker-compose를 통해 다중 브로커를 만들고 실행해보자kafka 브로커 3개로 구성된 클러스터 생성포트는 9092, 9093, 9094로 설정 (ec2 인스턴스 보안설정
velog.io
https://devocean.sk.com/blog/techBoardDetail.do?ID=163980
Kafka-UI Tool 을 이용하여 Kafka 관리하기
devocean.sk.com
https://livelyoneweek.tistory.com/53
스프링 부트 동일 Apllication 여러 포트로 구동 with (인텔리제이)
인텔리제이로 스프링 부트 구동 시 application 을 다른 포트로 돌리는 방법 ✨ MSA 구조를 공부 하는 도중, 연습용으로 여러 포트의 어플리케이션 구동이 필요하였다. build를 한 후 터미널에서 java -j
livelyoneweek.tistory.com
https://gksdudrb922.tistory.com/146
[Intellij] 환경 변수 등록
인텔리제이에서 시스템 환경 변수를 사용하고 싶어서 export PASSWORD=1234 이렇게 로컬에 환경 변수를 지정하고 System.getenv("PASSWORD") 이렇게 환경 변수를 꺼내서 사용하면 된다는데... 나의 경우는 되
gksdudrb922.tistory.com
'kafka' 카테고리의 다른 글
| Kafka - Producer 메시지 분배 전략(파티셔닝 전략)과 배치(feat. 하나의 파티션으로만 메시지가 전송된다?) (0) | 2024.06.06 |
|---|---|
| 카프카(Kafka)를 스프링부트와 함께 사용해보자! (1) | 2023.12.14 |
| 카프카(Kafka)는 어떻게 사용하는가? (0) | 2023.12.09 |

