들어가기
현재 진행하는 프로젝트는 지도 위에 게시 글을 작성하는 웹 사이트이다. 게시글 페이지에 접근 시 위도, 경도의 정보와 게시글이 가지는 기본적인 정보 및 좋아요, 댓글, 댓글 좋아요 등 정보들을 확인할 수 있도록 하였다. 사용자가 게시글 페이지에 접근 시, 프론트 서버에서는 백엔드에 한번 접근 시 위 정보들을 모두 얻지만, 백엔드 서버에서 DB에 접근하는 횟수는 4번이다. DB 접근할 때마다 얻는 내용은 아래와 같다.
- 게시글 상세 정보 조회
- 게시글에 회원이 좋아요를 눌렀는지 조회
- 게시글에 달린 댓글 리스트 조회
- 댓글마다 회원이 좋아요를 눌렀는지 조회
게시글 페이지를 들어갈 시, 위 4번의 DB에 접근하는 메서드가 실행된다. 서버는 DB에 접근하는 경우에 비용이 발생하므로 최적화를 위해선 DB 접근 횟수를 최소화하는 것이 중요하다.
결론부터 말하자면 4회 접근을 2회 접근으로 최소화하였다. 아무리 생각해도 1회 접근으로는 줄일 수가 없었다.
이 글에서는 Mybatis ResultMap, Collection을 사용하여 DB 접근을 어떻게 최소화했는지에 대해 작성하였다.
ResultMap에 관한 내용을 https://khdscor.tistory.com/91를 참고하길 바란다.
본론
우선 4가지 DB 접근 메서드를 확인해보겠다. 각각 mapper 인터페이스와 mapper.xml에 작성한 내용이다.
주요 테이블은 게시글(article), 게시글 좋아요(article_like), 댓글(comment), 댓글 좋아요(comment_like), 사용자(member)가 있으며 사용되는 테이블들의 ERD는 아래와 같다.

dto의 세부적인 내용은 크게 중요하지 않다고 판단하여 따로 글에 넣지는 않았다.
이제 작성된 메서드들을 살펴보자.
1. 게시글 상세 정보 조회
//mapper 인터페이스 내 메서드
ArticleDetailsDto findArticleDetails(Long articleId);
//mapper.xml
<select id="findArticleDetails" resultType="ArticleDetailsDto">
SELECT distinct a.id, a.title, a.content, a.latitude, a.longitude, a.member_id, m.nick_name,
m.image_url, a.create_date, count(l.id)
FROM article a JOIN member m ON a.member_id = m.id
LEFT JOIN article_like l ON a.id = l.article_id
WHERE a.id = #{articleId}
GROUP BY a.id
</select>
게시글에 대한 기본적인 내용을 보여주며 게시글 아이디, 게시글 제목, 게시글 내용, 위도, 경도, 게시글 작성 일, 게시글 좋아요 수 및 게시글 작성자 정보가 들어있다.
article 테이블과 member 테이블 article_like 테이블이 연관되어 있고 article id로 그룹화를 하여 article_like의 총 수를 집계하고 있다.
2. 게시글에 회원이 좋아요를 눌렀는지 조회
//mapper 인터페이스 내 메서드
boolean existsMyLike(ArticleLikeDto articleLikeDto);
//mapper.xml
<select id="existsMyLike" resultType="boolean">
SELECT EXISTS (
SELECT 1 FROM article_like
WHERE article_id = #{articleId} and member_id =#{memberId}
)
</select>
서브쿼리를 통해 회원(member_id)이 게시글(article_id)에 좋아요를 눌렀는지를 true, false로 반환한다.
3. 게시글에 달린 댓글 조회
// mapper 인터페이스 내 메서드
List<CommentResponse> findAllByArticleId(Long articleId);
//mapper.xml
<select id="findAllByArticleId" resultType="CommentResponse">
SELECT c.id, c.content, c.member_id, m.nick_name, m.image_url, c.create_date, count(l.id)
FROM comment c LEFT JOIN comment_like as l ON (c.id = l.comment_id)
LEFT JOIN member m ON (c.member_id = m.id)
WHERE c.article_id = #{articleId}
GROUP BY c.id
ORDER BY c.create_date desc
</select>
게시글(article_id)에 작성된 댓글들을 조회한다. 모든 댓글마다 가지고 있는 정보들을 조회하며 댓글 아이디, 내용, 작성 일, 댓글 작성자 정보, 댓글 좋아요 수 등을 보여준다.
comment 테이블과 member 테이블, comment_like 테이블이 연관되어 있으며 댓글 아이디로 그룹화하여 comment_like의 총 수를 집계하고 있다.
4. 댓글마다 회원이 좋아요를 눌렀는지 조회
//mapper 인터페이스 내 메서드
List<Long> findCommentIdsILiked(Long articleId, Long memberId);
//mapper.xml
<select id="findCommentIdsILiked" resultType="Long">
SELECT c.id FROM comment c JOIN comment_like l ON c.id = l.comment_id
WHERE c.article_id = #{articleId} AND l.member_id=#{memberId}
</select>
회원(member_id)이 좋아요를 누른 댓글들의 id 리스트를 조회한다.
comment 테이블과 comment_like 테이블이 연관되어 있다.
5. ResultMap을 통한 쿼리의 통합
이제 4가지 메서드들을 통합시켜 볼 것이다.
게시글 상세 조회 쿼리를 기반으로 ResultMap을 작성해 나가기로 하였다. 우선 게시글에 회원이 좋아요를 눌렀는지 조회하는 쿼리는 크게 어려울 것이 없었다. 왜냐하면 서브 쿼리로 true/false 값이 나오기 때문에 쿼리의 FROM 및 WHERE 절에 영향을 받지 않는다. 처음에는 서브쿼리를 사용하지 않고 통합하려 했지만 좋아요를 누른 회원의 member_id를 WHERE 절에 지정을 해주어야 한다. 이렇게 되면 comment 또한 member_id에 영향을 받기 때문에 의도한 결과가 나오지 않게 된다. 그렇기에 서브쿼리로 사용할 수밖에 없었다.
이제 댓글 리스트 조회와 회원이 좋아요를 누른 댓글 리스트를 조회하는 쿼리를 통합해야 한다. 처음 이들을 어떻게 통합할지 난감함이 컸었다. 둘다 리스트를 반환하는데, SELECT에서 서브쿼리를 사용하여 원하는 정보를 얻을 수 없기 때문이다.
SELECT에서 사용되는 서브쿼리를 '스칼라 서브쿼리'라고 하는데, 스칼라 서브쿼리는 단일 레코드만 조회가 가능하다.
만약 이를 무시하고 쿼리를 실행시킨다면 아래와 같은 에러가 날 것이다.(실제로 했을 때 아래의 문구가 나왔다...)
Scalar subquery contains more than one row; SQL statement
결국 스칼라 서브쿼리는 리스트를 반환할 수 없기에 서브쿼리의 사용이 제한된다. 큰 틀의 쿼리에 FROM 절과 WHERE 절을 잘 조합해서 원하는 결과를 끌어내야 한다.
댓글은 댓글을 작성한 회원의 정보도 필요하다. 즉 JOIN이 아래와 같아진다.
article join member, article join comment, comment join member
여기에 댓글 좋아요도 필요하기에 아래와 같아진다.
article join member, article join comment, comment join member, comment join commentLike
JOIN이 4번이나 사용되었다…
보기에도 복잡한데, 댓글 리스트 조회와 좋아요한 댓글 리스트 조회가 하나의 쿼리에 담을 수 없는 이유가 있다.
회원이 좋아요를 누른 댓글을 조회하려면 필히 comment_like 내 member_id를 WHERE 절에 지정해야 한다.
하지만 댓글 리스트 조회는 댓글 좋아요를 누른 회원의 member_id에 영향을 받지 않아야 한다.
만약 WHERE 절에 member_id를 지정하게 되면 댓글 리스트는 회원이 좋아요를 누른 댓글들만 나오게 될 것이다.
ResultMap의 기능 중 하나인 select 문 안에 select 문을 넣을 수 있는 기능을 사용하는 것도 생각해 보았지만 n+1 문제가 생기기 때문에 이 방법 또한 사용할 수 없다.
결국 댓글 리스트와 좋아요한 댓글을 조회하는 메서드는 통합될 수 없다고 판단하여 댓글 리스트만을 통합시키기로 하였다.
하지만 여기서 하나의 문제가 더 발생하였다.
게시글의 총 좋아요 수를 뽑아내는데 GROUP BY를 사용하고 있는데 댓글당 총 좋아요 수를 뽑아내기 위해선 GROUP BY로 comment_id를 지정해야 한다. 즉, 게시글 총 좋아요 수던지 댓글당 총 좋아요 수던지 둘 중 하나만을 조회할 수 있는 것이다.
계속 제안되는 해결 방법들이 막히고 있다..!
어떤 블로그 글에서 읽었는데 쿼리 하나가 몇 천 줄이 나있는 것도 있다고 한다. 아마 이런 식으로 조건들을 추가해 나갔기 때문일 것이다.
한참 고민을 하던 중 떠오른 방법은 서브쿼리였다. 스칼라 서브쿼리는 단일 레코드만 반환 가능하기에 댓글 리스트 조회를 생각할 때 제외시켰었는데, 생각해 보면 게시글 총 수는 단일 레코드이기에 서브쿼리를 사용하는데 전혀 지장이 없는 것이다..!
GROUP BY를 게시글 총 좋아요 수를 위해 사용하지 않고 댓글 당 좋아요 총 수를 위해 사용하고 comment_id로 지정을 하고자 하였다.
내가 생각한 의견이긴 했지만 article에 연결된 comment로 group by를 잡는다니...과연 될지 의문이 들긴 하였다. FROM을 article로 시작하는데 GROUP BY를 JOIN으로 연결한 comments의 필드로 잡는 것이니 말이다.
하지만 전체적인 연결을 확인해 보면 카티젼 곱의 위험도 없었고 문제는 없었다.
아래는 연결도를 이미지화 한 것이다.
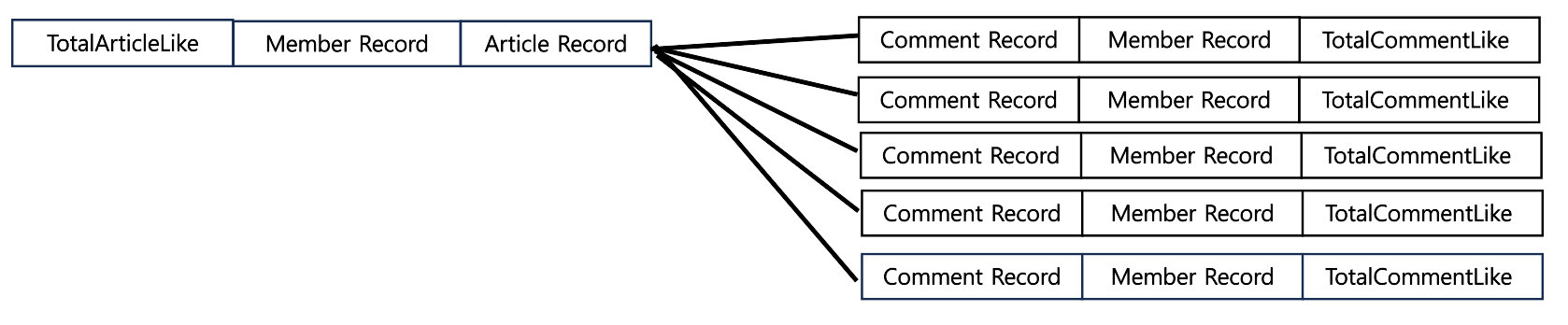
실제로 해보니 문제없이 실행되었다!
이렇게 comments 를 어떻게 가져올지에 대한 문제를 해결하였다.
회원이 좋아요한 댓글 리스트 조회 기능을 제외한 mapper.xml 내 쿼리는 같다.
<select id="findArticleDetails" resultMap="ArticleDetails">
SELECT a.id as articleId,
(SELECT EXISTS ( SELECT 1 FROM article_like
WHERE article_id = #{articleId} and member_id =#{memberId} )) as articleLike,
a.id as id, a.title as title, a.content as content,
a.latitude as latitude, a.longitude as longitude, a.member_id as writerId,
m.nick_name as writerName, m.image_url as writerImageUrl, a.create_date as createDate,
(SELECT count(l.id) FROM article a LEFT JOIN article_like l ON a.id = l.article_id
WHERE a.id = #{articleId} GROUP BY a.id ) as totalLikes,
c.id as commentId, c.content as commentContent, c.member_id as memberId, cm.nick_name as nickName,
cm.image_url as imageUrl, c.create_date as commentCreateDate, count(distinct cl.id) as commentTotalLikes
FROM article a JOIN member m ON (a.member_id = m.id)
LEFT JOIN comment c ON (a.id = c.article_id) LEFT JOIN comment_like cl ON c.id = cl.comment_id
LEFT JOIN member cm ON c.member_id = cm.id
WHERE a.id = #{articleId}
GROUP BY c.id
</select>
<resultMap id="ArticleDetails" type="ArticlePageDto">
<id property="articleId" column="articleId"/>
<result property="articleLike" column="articleLike"/>
<association property="articleDetails" javaType="ArticleDetailsDto">
<id property="id" column="id"/>
<result property="title" column="title"/>
<result property="content" column="content"/>
<result property="latitude" column="latitude"/>
<result property="longitude" column="longitude"/>
<result property="writerId" column="writerId"/>
<result property="writerName" column="writerName"/>
<result property="writerImageUrl" column="writerImageUrl"/>
<result property="createDate" column="createDate"/>
<result property="totalLikes" column="totalLikes"/>
</association>
<collection property="comments" notNullColumn="commentId"
ofType="foot.footprint.domain.comment.dto.CommentsDto">
<id property="commentId" column="commentId"/>
<result property="commentContent" column="commentContent"/>
<result property="memberId" column="memberId"/>
<result property="nickName" column="nickName"/>
<result property="imageUrl" column="imageUrl"/>
<result property="commentCreateDate" column="commentCreateDate"/>
<result property="commentTotalLikes" column="commentTotalLikes"/>
</collection>
</resultMap>
이제 회원이 좋아요한 댓글들을 조회하는 쿼리만 남았다. 지금까지 도출된 사항을 하나하나 나열해 보자.
- member_id를 서브쿼리가 아니라 큰 틀이 되는 쿼리에서는 사용하면 안 된다.
- 로그인 한 상황에서 게시 글을 보았을 때, 댓글들에 내가 좋아요를 눌렀는지 안 눌렀는지가 표시가 되어야 한다. 즉, member_id에 해당하는 member가 좋아요를 누른 comment_id의 리스트가 필요하다.
- comment_id의 리스트는 스칼라 서브쿼리로 구현할 수 없다.
- resultMap의 기능 중 하나인 select 문 안에 select 문을 넣는 것은 n+1 문제를 야기한다.
기본 쿼리에서 member_id를 사용하고 서브쿼리로 member_id에 종속되지 않는 값들을 가져오는 것은 어떨지 생각도 해보았다. 하지만 comments가 다중 행을 조회하기에 문제가 생긴다.
결국 좋아요한 댓글 리스트 조회는 다른 쿼리로 조회하기로 하였다.
이 쿼리는 처음 쿼리를 그대로 차용하였다.
원래 계획인 4회 조회를 1회 조회가 아닌 2회 조회로 변경한 것이다.
이제 쿼리 통합으로 인해 성능 향상이 얼마나 이루어졌는지 확인해 보자.
우선 postman API를 통해 1회 실행 시의 시간 비교이다.
쿼리 통합 전

쿼리 통합 후
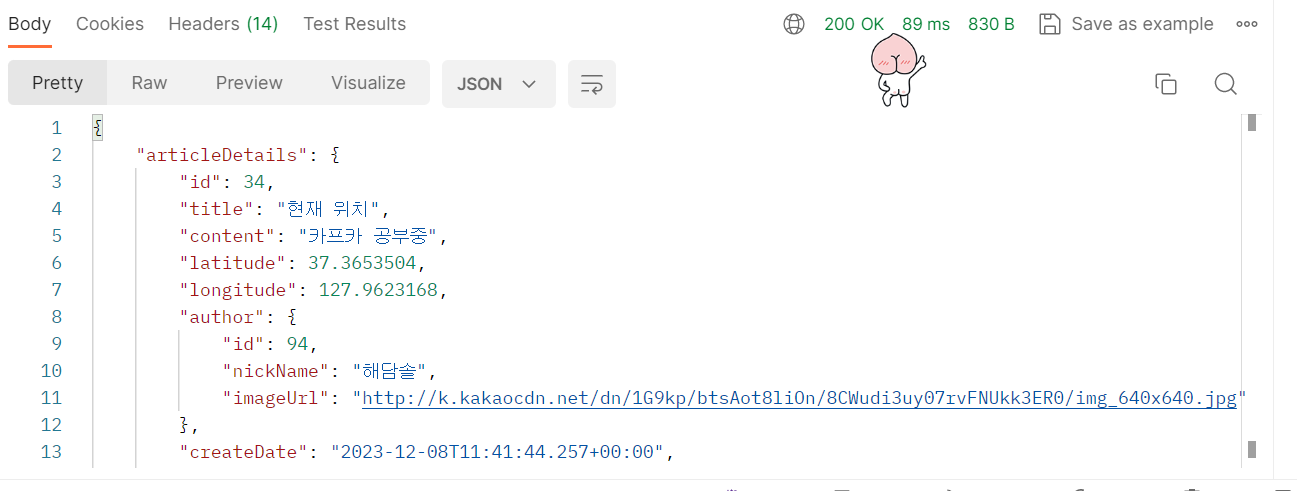
시간이 146ms에서 89ms로 줄어든 것을 확인할 수 있다.(여러 번 실행한 값 중 적당한 값을 가져온 것이며, 여러 번 실행해도 모두 비슷한 결과가 나왔다.)
이번엔 Jmeter를 통해 1000번의 트래픽을 날려보자.
Jmeter 사용하는 방법은 https://creampuffy.tistory.com/209를 참고하길 바란다.
쿼리 통합 전 - 1000번의 트래픽

쿼리 통합 후 - 1000번의 트래픽

시간이 3727ms에서 2426ms로 줄어든 것을 확인할 수 있다.(여러 번 실행한 값 중 적당한 값을 가져온 것이며, 여러 번 실행해도 모두 비슷한 결과가 나왔다.)
이렇게 DB 접근 횟수를 줄여서 성능 향상을 이룰 수 있었다.
6. 추가 부분 - 레디스 캐싱을 고려한 리펙토링
아쉽게도 여기서 끝나지 않았다. 레디스라는 것을 도입하여 캐시 기능을 사용하는데 문제가 생겼다. 게시 글은 로그인한 회원이나 로그인하지 않은 회원 모두 접근할 수가 있다. 레디스 캐시에는 로그인이 필요 없는 정보 정보 즉, member_id가 필요하지 않은 정보들을 저장해야 한다. 그래야 비 로그인 회원의 DB 접근도 레디스 캐싱을 통해 성능 향상을 이룰 수 있기 때문이다.
사용자 정보도 포함하여 레디스에 저장하면 사용자마다 게시글 정보가 저장될 테니 공간에 부담도 되고 말이다.
위에서 통합한 2개의 쿼리는 모두 로그인한 정보를 사용한다.
이런 생각도 하였다. 로그인하지 않았을 때 쿼리 상 member_id 부분을 null로 하면 되지 않을까? 메서드로부터 반환받은 값들을 가공한 형태로 캐시에 저장하는 것이다.
하지만 로그인하였을 겨우, 로그인 정보를 위해 다시 한번 쿼리 메서드를 실행해야 하므로 레디스 캐시에 의미가 없어진다.
여기서 생각한 방법은 로그인 정보를 조회하는 쿼리와, 비 로그인 정보를 조회하는 쿼리 2가지로 나누는 것이다. DB접근은 2회로 동일하기에 변하는 것은 없다. 더욱이 비 로그인 정보를 레디스에 저장하면 로그인하지 않은 회원이나 로그인한 회원이나 모두 레디스 캐시 기능을 활용할 수 있다.
이전 통합 쿼리는 게시글 상세 정보, 회원이 게시글에 좋아요를 했는지, 게시글 내 댓글 리스트 조회하는 쿼리와 회원이 좋아요한 댓글 아이디 리스트 조회 쿼리로 구분되었었다.
이를 로그인 기준으로 나누면 게시글 상세 정보, 게시글 내 댓글 리스트 조회 쿼리와 회원이 게시글에 좋아요를 눌렀는지, 회원이 좋아요한 댓글 리스트 조회, 이렇게 두 가지 쿼리로 바꾸었다.
게시글에 좋아요를 했는지 조회하는 것은 서브 쿼리였기 때문에 이동하는데 제한이 없었다.
결론은 아래와 같다.
1. 로그인하지 않은 회원의 게시 글 접근 - 첫 접근이었을 경우 비 로그인 정보 조회 쿼리 1회로 DB 접근은 총 1회이다. 이후 레디스에 비 로그인 정보를 저장한다. 두 번째 접근일 경우 레디스에 저장된 비 로그인 정보를 가져오기 때문에 DB접근은 총 0회이다.
2. 로그인 한 회원의 게시 글 접근 - 첫 접근이었을 경우 비 로그인 정보 조회 쿼리 1회, 로그인 정보 조회 쿼리 1회로 DB 접근은 총 2회이다. 이후 레디스에 비 로그인 정보를 저장한다. 두 번째 접근일 경우 레디스에 저장된 비 로그인 정보를 가져오고 로그인 정보 조회 쿼리 1회로 DB 접근은 총 1회이다.
결국 로그인 하지 않은 회원이나 로그인한 회원이나 모두 레디스를 통한 성능 향상을 이루었다.
수정된 쿼리는 아래와 같다.
1. 비 로그인 정보 조회 쿼리
<select id="findArticleDetails" resultMap="ArticleDetails">
SELECT a.id as articleId,
a.id as id, a.title as title, a.content as content,
a.latitude as latitude, a.longitude as longitude, a.public_map as publicMap,
a.private_map as privateMap, a.member_id as writerId,
m.nick_name as writerName, m.image_url as writerImageUrl, a.create_date as createDate,
(SELECT count(l.id) FROM article a LEFT JOIN article_like l ON a.id = l.article_id
WHERE a.id = #{articleId} GROUP BY a.id ) as totalLikes,
c.id as commentId, c.content as commentContent, c.member_id as memberId, cm.nick_name as nickName,
cm.image_url as imageUrl, c.create_date as commentCreateDate, count(distinct cl.id) as commentTotalLikes
FROM article a JOIN member m ON (a.member_id = m.id)
LEFT JOIN comment c ON (a.id = c.article_id) LEFT JOIN comment_like cl ON c.id = cl.comment_id
LEFT JOIN member cm ON c.member_id = cm.id
WHERE a.id = #{articleId}
GROUP BY c.id ORDER BY c.id DESC LIMIT 10
</select>
<resultMap id="ArticleDetails" type="ArticlePageDto">
<id property="articleId" column="articleId"/>
<association property="articleDetails" javaType="ArticleDetailsDto">
<id property="id" column="id"/>
<result property="title" column="title"/>
<result property="content" column="content"/>
<result property="latitude" column="latitude"/>
<result property="longitude" column="longitude"/>
<result property="publicMap" column="publicMap"/>
<result property="privateMap" column="privateMap"/>
<result property="writerId" column="writerId"/>
<result property="writerName" column="writerName"/>
<result property="writerImageUrl" column="writerImageUrl"/>
<result property="createDate" column="createDate"/>
<result property="totalLikes" column="totalLikes"/>
</association>
<collection property="comments" notNullColumn="commentId"
ofType="foot.footprint.domain.comment.dto.CommentsDto">
<id property="commentId" column="commentId"/>
<result property="commentContent" column="commentContent"/>
<result property="memberId" column="memberId"/>
<result property="nickName" column="nickName"/>
<result property="imageUrl" column="imageUrl"/>
<result property="commentCreateDate" column="commentCreateDate"/>
<result property="commentTotalLikes" column="commentTotalLikes"/>
</collection>
</resultMap>
2. 로그인 정보 조회 쿼리
<select id="findArticlePrivateDetails" resultMap="ArticlePrivateDetails">
SELECT
a.id as articleId,
(SELECT EXISTS ( SELECT 1 FROM article_like
WHERE article_id = #{articleId} and member_id =#{memberId} )) as articleLike,
c.id as commentId,
l.member_id as memberId
FROM article a LEFT JOIN comment c ON a.id = c.article_id
LEFT JOIN comment_like l ON c.id = l.comment_id
WHERE a.id = #{articleId}
</select>
<resultMap id="ArticlePrivateDetails" type="ArticlePrivateDetailsDto">
<id property="articleId" column="articleId"/>
<id property="articleLike" column="articleLike"/>
<collection property="commentLikes" notNullColumn="commentId"
ofType="foot.footprint.domain.article.dto.articleDetails.MyCommentLikesInArticle">
<id property="commentId" column="commentId"/>
<result property="memberId" column="memberId"/>
</collection>
</resultMap>
결론
구현한 코드가 살짝 복잡해 보이긴 하지만 몇 천 줄 이상의 쿼리도 존재한다고 하니 이 정도는 아직 애송이 수준일 것이다. 성능 향상을 위해 쿼리 하나를 생각할 때도 많은 시간이 필요하다는 것을 이해할 수 있었던 시간이었다. 앞으로도 성능향상을 위해 쿼리 하나하나 유심히 살펴봐야겠다.
참고
https://creampuffy.tistory.com/209
Apache JMeter를 이용한 부하 테스트 및 리포트 생성
서버의 성능을 최적화하기 위해선 어떤 작업이 필요할까요? 어떤 지표를 기준으로 성능을 측정할 것인지, 정의된 지표에 영향을 미치는 변수에는 무엇이 있는지, 해당 변수들의 변화가 성능에
creampuffy.tistory.com
[MYSQL] 📚 서브쿼리 개념 & 문법 💯 정리
서브쿼리(Subquery) 서브쿼리(subquery)란 다른 쿼리 내부에 포함되어 있는 SELETE 문을 의미한다. 서브쿼리를 포함하고 있는 쿼리를 외부쿼리(outer query)라고 부르며, 서브쿼리는 내부쿼리(inner query)라
inpa.tistory.com
'프로젝트 관련' 카테고리의 다른 글
| Spring boot with React: STOMP를 통해 채팅 시스템을 구현해보자(With Mysql, MongoDB)(2) (4) | 2024.05.17 |
|---|---|
| Spring boot with React: STOMP를 통해 채팅 시스템을 구현해보자(With Mysql, MongoDB)(1) (8) | 2024.05.13 |
| Springboot With React: 커서 기반 페이징 기법을 통한 댓글 무한 스크롤 구현 (1) | 2023.10.19 |
| 스프링부트 With Mysql - easyRandom을 통한 bulk Insert 및 Index 적용 (0) | 2023.08.03 |
| springboot delete시 DB접근, 쿼리 횟수에 대한 고찰(mybatis, jpa) (0) | 2023.06.24 |


