들어가기
서버를 배포할 때 항상 나오는 용어가 있다. '로드 밸런싱'.
로드 밸런싱은 사용자의 요청으로 발생한 트래픽을 하나의 서버만이 아니라 여러 서버가 나눠서 받는 것을 말한다.
이러한 로드 밸런싱을 통해 하나의 서버로 트래픽이 몰려 과부하가 걸리는 것을 방지할 수 있다.
로드 밸런싱을 이루는 방법은 다양하게 있는데, 그중 오케스트레이션 도구를 사용하는 것이다.
'오케스트레이션 도구'란 여러 개의 서비스를 연결하여 커다란 클러스터로 만들어 관리하는 것으로 배포, 관리, 확장, 네트워킹을 자동화할 수 있다. 여러 개의 서비스는 같은 서비스가 여러 개 일 수 있다는 말이고, 트래픽을 여러 서버가 나눠서 받는 로드 밸런싱을 구현할 수도 있다.
서버 내의 서비스가 포화상태면 서버를 병렬로 추가하여 쉽게 확장시킬 수 있고, 이러한 여러 대의 서버를 클러스터로 만들어 관리한다.
오케스트레이션 도구에는 도커 스웜(Docker Swarm), 쿠버네티스(Kubernetes), 아파치 메소스(Apache Mesos) 등이 있다.
이번 글에서는 오케스트레이션 도구 중 하나인 '도커 스웜'을 사용해 볼 것이다.
본론
도커를 사용하면서 여러 개의 컨테이너를 통해 서비스를 쉽게 구현할 수가 있었다. 하지만 하나의 서버에서 컨테이너의 수는 한계가 있을 수밖에 없다. 이럴 경우엔 서버를 확장해야 하는데 '스케일 업' 방식과 '스케일 아웃' 방식이 있다. 스케일 업은 기존 서버를 성능이 좋은 서버로 업그레이드하는 것이고 스케일 아웃은 같은 서버를 여러 대 추가하는 것이다.
일반적으로 기존 서버를 업그레이드 하는 비용보다 단순히 동일한 서버를 한 대 추가하는 것이 간단하기에 스케일 아웃이 권장되고, 이러한 스케일 아웃을 하여 여러 대에 여러 컨테이너를 운용하는 것이 오케스트레이션 도구의 핵심이다.
도커 스웜을 통해 여러 서버를 동시 운용하여 관리할 수 있는데, 어떤 서버에 어느 컨테이너를 할당할지에 대한 스케줄러, 로드밸런서 문제, 클러스터 내의 서버가 다운됐을 때 고가용성을 어떻게 보장할지 등을 해결할 수 있다.
이제 본격적으로 도커 스웜을 어떻게 다루는지에 대해 알아보자. 도커 스웜은 도커 엔진 자체에 내장되어 있기 때문에 도커를 설치하였다면 스웜 모드는 별도의 설치를 필요로 하지 않는다. docker info를 통해 스웜 정보를 확인할 수 있다.

아직 스웜을 시작하지 않았기 때문에 비활성화되어 있다.
한 가지 주의점을 말하자면 서버 클러스터링을 할 때는 반드시 각 서버의 시각을 동기화해야 한다. 서버 간에 설정된 시각이 다를 경우 예상치 못한 오류가 발생할 수 있기 때문이다.
1. 도커 스웜 구조
스웜모드는 매니저 노드와 워커 노드로 구성되어 있다. 워커 노드는 실제 컨테이너가 생성되어 운용되는 서버이고 매니저 노드는 워커 노드를 관리하기 위한 서버이다. 그렇다고 매니저 노드에 컨테이너가 생성될 수 없는 것은 아니다. 매니저 노드는 워커 노드의 역할을 기본으로 하고 있기 때문이다.

워커 노드는 0개 있어도 되지만 매니저 노드는 최소한 1개 있어야 하는데, 매니저 노드가 워커 노드의 역할도 가지고 있어 매니저 노드만으로 스웜 클러스터를 구성할 수 있기 때문이다.
일반적으로 워커노드와 매니저 노드를 구분해서 사용하는 것이 권장된다.
2. 도커 스웜 클러스터 구축
우선 도커 스웜 클러스터를 사용하려면 스웜모드를 활성화해야 한다. 매니저가 될 서버에서 docker swarm init 명령어를 입력하면 시작할 수 있다. --advertise-addr [IP 주소] 옵션을 통해 다른 서버들이 매니저 노드에 접근할 IP 주소를 등록을 할 수 있다.

출력 결과 중 docker swarm join --token ~ 13.209.26.239:2377 문장이 있다. 이 문장을 워커 노드로 선정한 서버에서 입력하면 도커 클러스터에 포함될 수 있다.
여기서 주의할 점이 있다! 필자는 워커 서버에 위의 명령어를 입력하였더니 아래와 같은 에러가 발생했었다.
"Error response from daemon: Timeout was reached before node joined. The attempt to join the swarm will continue in the background. Use the "docker info" command to see the current swarm status of your node."
이는 매니저 서버에 시도하였지만 연결을 못했다는 말인데... 확인해 본 결과 사용하고 있던 aws 서버의 2377 포트를 열지 않았던 것이었다..! 스웜 매니저는 기본적으로 TCP 2377번 포트를 사용하기에 무조건 열어주어야 한다.
포트를 열어준 후 명령어를 입력하면 아래와 같이 나오면 정상적으로 워커노드로서 스웜 클러스터에 추가된 것이다.

이후 매니저 노드에서 docker node ls 를 입력하면 워커노드가 제대로 추가된 것을 확인할 수 있다. ID 끝에 *가 있는 것이 현재 서버이다. Leader은 의미 그대로 운영자 노드를 뜻하고 매니저 노드들 중에서 리더가 될 수 있다. 최초 init 명령어를 한 매니저 노드가 Leader가 된다.

이후 추가로 매니저 노드, 워커 노드를 추가하기 위한 토큰을 확인하려면
docker swarm join-token manager
docker swarm join-token worker
를 입력하면 토큰을 확인할 수 있다.
만약 스웜 클러스터에 추가 된 서버를 다시 종료시키려면 docker swarm leave 명령어를 스웜을 비활성화시킬 수 있다. 매니저 노드일 경우 --force 옵션을 추가하여 비활성화 시킬 수 있다. 매니저 노드가 한 개 일 때 매니저 노드를 비활성화시키면 해당 스웜 클러스터는 사용 불가 상태가 되니 주의해야 된다.
비활성화시키면 아래와 같이 STATUS 값이 Down으로 인식이 된다.

이는 완전한 제거는 아니므로 docker node rm [ID]를 통해 제거를 해줘야 한다.
참고로 워커 노드를 매니저 노드로, 매니저 노드를 워커 노드로 변경하려면 각각 docker node promote, docker node demote 명령어를 해당 노드에서 입력하면 된다. 만약 매니저 노드가 1개라면 demote 명령어를 사용할 수 없다. 매니저 노드가 여러 개일 때 리더 노드에서 demote를 입력하면 다른 매니저 노드 중 새로운 리더를 선출한다.
만약 특정 노드에 컨테이너를 할당하고 싶지 않을 때는 어떻게 해야 할까?
docker node update 명령어를 사용하면 된다. --availability 옵션을 사용하며 아래의 명령어들을 봐보자.
docker node update --availability active manager // manager의 AVAILABILITY를 Active로 변경
docker node update --availability drain manager // manager의 AVAILABILITY를 Drain로 변경
docker node update --availability pause manager // manager의 AVAILABILITY를 Pause로 변경
Active 상태는 기본적으로 설정되는 상태로, 노드가 컨테이너를 할당받을 수 있음을 나타낸다.
Drain 상태는 일반적으로 매니저 노드에 설정하는 상태로, 노드에 문제가 생겨 일시적으로 사용하지 않는 상태이다. 이 상태에서는 컨테이너를 할당받을 수 없다. 컨테이너가 실행 도중에 Drain 상태로 변경 시 실행 중이던 컨테이너들은 모두 중지된다.
Pause 상태는 컨테이너를 더 이상 할당받지 않는 상태로, 컨테이너 실행 도중에 Pause로 변경해도 실행 중인 컨테이너가 중지되지 않는다.
아래는 매니저 노드를 Drain 상태로 변경 후 확인한 것이다.

3. 도커 스웜 서비스 운용
도커 스웜에서는 애플리케이션을 컨테이너로 실행한다는 말보다는 서비스로 실행한다고 말한다. 그 이유는 여러 개의 서버에 여러 개의 컨테이너가 실행되는 것이기에 단순한 하나의 컨테이너가 아니다. 그렇기에 여러 애플리케이션 컨테이너들을 하나로 표현하고자 하나의 서비스라고 말한다. 실행되는 컨테이너는 태스크(Task)라고 한다.
이러한 태스크들은 매니저, 워커 노드에 할당되어 실행이 된다. 이때 반복해서 생성된 태스크들을 레플리카(replica)라고 하며, 서비스에 설정된 레플리카의 수만큼의 태스크가 스웜 클러스터 내에 존재한다.
이제 이러한 서비스를 생성해 보자.
서비스는 오직 매니저 노드에서만 생성하고 제어할 수 있다. 매니저 노드에서 docker service create [이미지] 명령어를 통해 서비스를 시작할 수 있다. 아래는 ubuntu:14.04 이미지로 'hello world'를 출력하는 예제이다. 해당 명령어를 입력해 보자.
docker service create ubuntu:14.04 /bin/sh -c "while true; do echo hello world; sleep 1; done"
verify: Service converged가 출력되면 성공적으로 서비스가 생성된 것이다.
이후 docker service ls로 생성된 서비스들을 확인할 수 있다.

REPLICAS를 보면 1/1이라고 되어있는데 1개 중 1개의 서비스가 잘 실행되고 있다는 것이다.
그렇다면 0/1 은 무슨 의미일까? 에러가 난 것이다. 처음에 실행할 때는 잘 될 것 같았지만 에러가 발생했다..!
에러가 날 경우 아래와 같이 verify: Detected task failure가 출력된다.

위 문제는 명령어를 입력할 때 오타나 잘못된 내용을 입력하였을 경우 발생하는 문제다. 필자 같은 경우 -c를 입력하지 않아서 위와 같은 에러가 발생했었다...
만약 위의 에러가 난다면 명령어를 다시 한번 확인해 보자.
또 한 가지 주의할 점은 서비스 내의 컨테이너가 -d 옵션을 사용해 동작할 수 있는 이미지를 사용해야 한다. 예를 들어 위의 명령어는 우분트 이미지를 통해 특정 출력을 하도록 만든 컨테이너였다.
하지만 docker service create ubuntu:14.04 만 입력할 시 서비스가 생성됨과 동시에 컨테이너 내부를 차지하고 있는 프로세스가 없어 컨테이너가 정지될 것이고, 스웜 매니저는 서비스의 컨테이너가 장애가 생긴 것으로 판단해 컨테이너를 무한 반복 생성하게 될 것이다.
이번에는 nginx를 옵션을 추가하여 생성해 보자. 아래는 서비스 이름, 포트, 레플리카 수를 지정하여 서비스를 생성하는 명령어이다.
docker service create --name myweb --replicas 3 -p 80:80 nginx:latest
이번에는 레플리카가 3개이지 않은가? 실행하면 아래와 같이 3개의 running이 출력된다.

생성된 서비스를 제거하려면 docker service rm [서비스 이름] 명령어를 입력하면 된다.
그런데 생성된 3개의 컨테이너는 각각 어느 서버에서 실행이 되고 있을까?
docker service ps [서비스 이름] 명령어를 통해 확인할 수 있다.

위와 같이 매니저 노드에서만 이미지를 다운로드하고 실행하였지만 워커 노드의 아이피에도 컨테이너가 생성된 것을 알 수 있다. 그렇다고 위의 ip로만 애플리케이션에 접근할 수 있는 것은 아니다. 80번 포트를 연 것은 특정 ip가 아닌 도커 클러스터 자체의 80번 포트를 연 것이므로 도커 클러스터에 포함된 어느 서버에 ip든지 접근을 할 수가 있다.
어떤 서버의 ip로 들어갔을 때 어느 서버로 들어가는지는 기본적으로 라운드 로빈 방식을 통해 순차적으로 정해진다.
생성된 서비스는 docker service scale 명령어를 통해 레플리카셋의 수를 늘리거나 줄일 수 있다. 아래와 같이 레플리카의 셋의 수를 6으로 설정해 보자.
docker service scale myweb=6

보는 바와 같이 6개의 컨테이너가 실행 중이다.
특정 서버에서 docker ps 명령어를 입력하면 실제로 컨테이너가 실행 중인 것을 확인할 수 있다.

그런데 docker service ps 명령어를 통해 확인할 수 있는 정보중 어떤 서버인지를 구분해 주는 NODE 항목이 가독성이 떨어지지 않나? ip 주소를 통해 구분을 하지만 한 번에 서버들을 구분하기는 힘들다.
이럴 때는 각 서버별로 sudo hostnamectl set-hostname [지정할 이름] 명령어를 통해 서버 이름을 지정해 줄 수 있다. 아래는 변경한 사진이다.

가독성이 더 좋아지지 않았나?! 앞으로는 서버를 도커클러스터에 추가하자마자 호스트 이름을 지정해야겠다.
이렇듯 도커 스웜은 서비스 실행 명령어를 통해 각 서버에 컨테이너를 실행시킬 수 있다. 또한 장애가 일어났을 경우에 복구할 수 있는 기능을 갖췄다.
도커 스웜은 미리 지정한 레플리카 수보다 컨테이너가 부족하다면 부족한 수만큼 새로운 컨테이너 레플리카가 생성되도록 되어있다.
이는 특정 컨테이너가 장애가 나서 운용을 할 수가 없다면 해당 서버에 새로운 컨테이너를 생성한다.
즉, 장애가 일어났을 경우 복구가 자동으로 일어나는 것이다.
아래는 특정 노드의 컨테이너를 임의로 종료하였을 시 다시 새로 생성된 것을 보여준다.

특정 서버가 장애가 났다면 해당 서버에 있던 컨테이너의 수만큼 다른 서버에 컨테이너가 생성된다. 만약 장애가 해결된 후 다시 서버를 실행해오 최초의 상태처럼 균형을 이루며 원래대로 배치되지는 않는다.
이럴 때엔 scale를 1로 감소 후 다시 증가를 시키면 최초의 상태처럼 균형을 다시 맞출 수 있다.
이렇듯 레플리카셋의 수를 원하는 대로 조정하여 서버에 배치하는 방법도 있지만 모든 서버가 반드시 서버당 하나의 컨테이너만을 가지도록 할 수도 있다.
이는 글로벌(global) 모드라고 하며 스웜 클러스터를 모니터링하기 위한 에이전트 컨테이너 등을 생성해야 할 때 유용한 방법이다.
글로벌 모드는 아래와 같이 replicas를 입력하지 않고 --mode global을 옵션에 추가하여 적용할 수 있다.
docker service create --name global_web --mode golbal nginx
위의 명령어를 입력하였을 경우 아래와 같이 서버당 하나의 컨테이너가 실행되고 있는 것을 확인할 수 있다.

4. 롤링 업데이트
실행 중인 서비스의 버전이 업그레이드 됐을 때는 어떻게 해야 할까? 시행 중인 컨테이너마다 하나하나 업데이트를 실시해야 할까?
다행스럽게도 도커 스웜에는 '롤링 업데이트'라는 기능을 제공하는데, 롤링 업데이트는 서비스 내 컨테이너들의 이미지를 지정한 개수대로 순차적으로 업데이트하여 서비스 자체가 다운되는 시간 없이 컨테이너를 업데이트하는 것이다.
일반적인 경우 모든 컨테이너를 동시에 업데이트하면 서비스가 일시적으로 다운되지만, 롤링 업데이트는 순차적으로 업데이트를 하기에 하나를 업데이트 중이면 다른 컨테이너가 실행 중이다. 그렇기에 무중단 배포를 이룰 수 있다.
그렇다면 도커 스웜에서는 어떻게 롤링 업데이트를 실시할 수 있을까?
서비스 생성 시 아래와 같이 명령어를 입력할 수 있다.
docker service create --replicas 6 --name myweb --update-delay 10s --update-parallelism 2
--update-failure-action continure(또는 pause) nginx:1.10
서비스 생성 시 추가적인 옵션을 부여한다. --update-parallelism은 동시에 몇 개의 이미지를 업데이트할지,
--update-delay는 연속적인 업데이트 사이의 딜레이를 얼마나 할지, --update -failure-action는 업데이트 실패 시 해당 컨테이너를 어떻게 할지를 나타낸다.
이렇게 생성 후 docker service update 명령어를 입력하면 업데이트를 원하는 버전의 이미지가 도커 허브에 있다면 해당 이미지로 지정한 옵션에 따라 업데이트가 진행된다.
아래는 service update를 하기 전 서비스를 확인한 사진이다.

이제 아래와 같은 명령어를 입력해 보았다.
docker service update --image nginx:1.11 myweb
과연 어떻게 됐을까? 아래를 봐보자.

업데이트가 잘 된 것을 확인할 수 있다.
이후 롤링 업데이트의 설정은 docker service inspect --type service을 통해 다시 확인할 수 있다.
그런데 업데이트를 잘못해서 되돌리고 싶을 때에는 어떻게 할까? 단순히 롤백시키면 된다.
도커 스웜에서도 롤백하는 명령어가 존재하며, 아래와 같은 명령어를 입력하여 해결할 수 있다.
docker service rollback myweb
5. 도커 스웜 네트워크
위에서 언급했다시피 어느 서버의 IP 주소를 통해 서비스에 접근해도 라운드로빈 방식으로 스웜 클러스터 내의 모든 서버에 접근이 된다. 과연 어떤 방식의 네트워크가 구성되어 있을까?
스웜 모드는 여러 서버에 설치된 도커 엔진에 같은 컨테이너를 분산해서 설치하기 때문에 각 도커 데몬이 함께 묶인 네트워크 풀이 필요하다. 또한 외부에서 서비스로 접근하기 위한 라우팅 기능도 필요하다. 이러한 것들은 도커 스웜 클러스터를 생성함과 동시에 자동으로 네트워크 드라이브가 추가된다.
docker network ls를 통해 네트워크를 확인해 보자.

도커 스웜에서 사용하는 것은 ingress와 docker_gwbridge이다.
ingress 네트워크는 오버레이 네트워크를 기반으로 하며 로드 밸런싱과 라우팅 매시에 사용되며 스웜모드를 사용할 때만 유효하다. 오버레이 네트워크는 네트워크에 속한 모든 컨테이너가 같은 서버에 있는 컨테이너들처럼 통신이 가능하도록 하며 외부에서의 접근 또한 라운드 로빈 방식에 따라 컨테이너로 접근하도록 한다.
그렇다면 docker_gwbridge 네트워크는 무엇인가? 오버레이 네트워크를 사용하지 않는 컨테이너는 기본적으로 존재하는 브리지(bridge) 네트워크를 사용해 외부와 연결한다.
그러나 모든 오버레이 네트워크는 docker_gwbridge 네트워크와 함께 사용된다.
docker_gwbridge 네트워크는 도커 데몬에 물리적으로 연결되는 가상의 네트워크이며, 외부로 나가는 통신 및 오버레이 네트워크의 트래픽 종단점(VTEP) 역할을 담당한다.
아래의 그림을 봐보자.

위의 그림은 각각의 서버로의 접근이 이루어지고 있는 모습이다. 만약 도커 클러스터를 사용하지 않는다면, docker0라는 브리지 네트워크를 통해 해당 서버에서만 가지고 있는 컨테이너로 접근이 될 거이다.
하지만 도커 클러스터를 사용하고 있다면 docker_gwbridge를 통해 ingress 네트워크의 VIP(Virtual IP)로 접근이 되고 ingress 네트워크는 각각의 컨테이너에 라운드 로빈 방식으로 분산하도록 로드밸런싱을 구성한다.
만약 이를 테스트하고 싶다면 아래와 같은 이미지를 서비스로 실행해 보자. 어느 IP를 가지는 서버로 접근했는지 화면에 나타내는 서비스들로, 80 포트로 ip주소로 접근하였을 때, 시간이 지나고 다시 접근하거나 다른 브라우저로 접근하였을때 다른 매번 다른 ip주소가 뜰 것이니 참고하길 바란다.
docker service create --name loadbalance_test --replicas 4 -p 80:80 utyk/swarm_loadbalance_check:1.0
docker service create --name hostname -p 80:80 --replicas 4 alicek106/book:hostname
여기서 주의할 점이 있는데 2377 포트뿐만이 아니라 노드 사이의 통신을 위한 7946(tcp/udp), 인그레스 네트워크를 위한 4789(tcp/udp)를 추가로 열어주어야 한다는 것이다.
필자는 처음에 아무리 브라우저를 다시 열어도 같은 항상 같은 ip 주소가 떠서 적용을 확인하는데 어려움이 있었다...
포트를 연 후 서버 간의 통신이 원활히 되고 있는 것을 확인하려면 'doker insepect network [네트워크 이름]' 명령어를 입력 후 "Pears" 부분에 도커 클러스터에 가입된 서버의 IP 주소들이 전부 들어가 있는지 확인하자.

도커 클러스터를 생성 시 추가되는 ingress 네트워크를 이용해도 되지만 사용자 정의 네트워크를 오버레이 네트워크로 생성하여도 똑같이 적용할 수 있다.
docker network create --driver overlay --subnet 172.200.1.0/24 --gateway 172.200.1.1 overlay-net
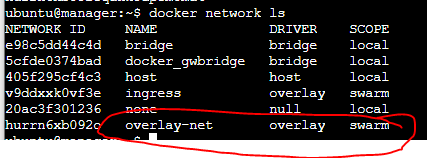
위와 같이 네트워크를 생성 후 서비스 생성 시 네트워크를 지정해 주면 된다.
docker service create --name myweb --replicas 3 -p 80:80 --network overlay-net nginx:latest
6. 도커 컴포즈를 통한 연결
도커 컴포즈는 파일 하나로 여러 컨테이너들을 동시에 실행시키는 것이다. 놀랍게도 이를 스웜과도 함께 적용할 수가 있다.
컨테이너들을 운용할 때에는 yaml 파일로 컨포즈 파일을 생성한다고 하였는데, 스웜모드와 함께할 때는 yaml 파일로 스택(stack)을 생성한다고 한다.
yaml 파일로 스택을 생성하면 yaml 파일에 정의된 서비스가 스웜 모드의 클러스터에서 일괄적으로 생성된다.
yaml 파일에 정의된 서비스가 스웜 모드의 서비스로 변환된 것이다.
스택은 매니저에 의해서만 생성, 삭제될 수가 있기에 매니저로 명령어들을 입력해야 한다.
작성된 yml 파일을 토대로 스택을 생성하기 위해서 아래와 같은 명령어를 입력한다.
docker stack deploy -c docker-compose.yml mystack
아래는 docker-composer.yml 파일 내용이다.
version: '3.8'
services:
footprint-redis:
image: redis:latest
container_name: footprint-redis
ports:
- "6379:6379"
footprint-backend:
build:
context: ./backend/footprint
dockerfile: Dockerfile
container_name: footprint-backend
ports:
- "8080:8080"
footprint-frontend:
build:
context: ./frontend/footprint
dockerfile: Dockerfile
container_name: footprint-frontend
ports:
- "80:3000"
위 파일을 스웜 클러스터를 위한 스택 명령어로 실행하면 아래와 같이 뜨는데 확인할 점은 "Ignoring deprecated options"이다.

보는 바와 같이 container_name이 지원되지 않는 형식이라고 한다. 스택과 컴포즈는 유사한 점이 많지만 컴포즈에서 사용되던 것 중 일부가 스택에서 지원이 안되기에 스택으로 실행 시 지원이 되지 않는 부분은 무시하며 실행된다.
container_name이 그렇고 depends_on, link 등 호환이 되지 않는 부분들이 있다. 그렇다고 에러를 발생하는 것이 아니라 단순히 무시하는 것이므로 위와 같은 출력이 나오면 수정하면 된다.
그런데 위와 같은 파일로는 아래와 같이 문제가 생겼다...


도커 서비스를 조회했을 때 redis만 잘 실행되고 backend는 제대로 실행되지 않고 있고 frontend는 아예 실행 흔적이 없다.
스택을 살펴보니 ERROR에 해당 이미지가 없다고 생기는 에러를 발견했다.
확인해 보니 매니저에서 build로 폴더를 이미지로 변경을 하였을 때, 매니저는 문제가 없지만, 워커는 해당 폴더가 존재하지 않기 때문에 이러한 에러가 발생하는 것이라는 것을 알았다..!
즉, 워커에도 폴더를 생성하거나, 이미지를 미리 만들어 두면 문제는 해결할 수 있는 것이다. 혹은 도커 허브에 이미지를 업로드하면 된다.
우선 redis에 부분만을 남겨두고 테스트를 진행하였다.
실행을 잘되었어 docker stack ls, docker stack ps mystack 명령어를 통해
네트워크 자동 생성
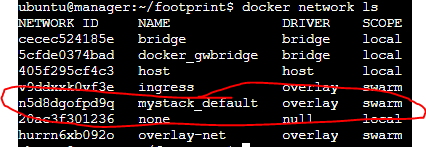
아래는 docker stack ls 명령어를 실행했을 때의 사진이다.

아래는 docker service ls 명령어를 실행했을 때의 사진이다.

문제없이 실행되는 것을 확인할 수 있다.
이후 실행되는 컨테이너의 수를 조절하기 위해 아래와 같은 명령어를 입력할 수 있다.
docker service scale mystack_footprint-redis=6
결론
이렇게 도커 스웜을 사용해 보았다.
도커 스웜과 같은 오케스트레이션 도구에서는 여러 서버를 두어 부하를 분산시키고 장애가 발생 시 이를 복구하는 특징이 있다.
대규모 서비스를 운용함에 있어 오케스트레이션 도구를 사용하는 것은 거의 필수로 다가왔고 많이 익숙해져야겠다고 생각했다.
다른 오케스트레이션 도구 중 쿠버네티스가 있는데, 현재 대부분의 회사에서는 쿠버네티스를 사용하고 있다고 한다.
도커 스웜과 같은 오케스트레이션 도구지만 쿠버네티스는 더욱 복잡하다고 한다.
다음에는 쿠버네티스를 공부해 봐야겠다.
참고
시작하세요! 도커/쿠버네티스 - 용찬호
https://forums.docker.com/t/fail-join-node-as-worker/48321
Fail join node as Worker
Hello everyone, I am trying to form a Docker Swarm with a manager node and 2 workers. The problem is that the worker nodes do not join the swarm, and they show me the following error: docker swarm join \ --token SWMTKN-1-40dp45dybgfah9wcunovtz9vy4dorbv3mig
forums.docker.com
https://yoo11052.tistory.com/184
[Docker] Docker Swarm Network의 종류
도커 스웜 네트워크 스웜 모드는 여러 개의 노드에 같은 컨테이너를 분산해서 할당하기 때문에 각 노드를 하나로 묶어줄 네트워크가 필요합니다. 뿐만 아니라 서비스를 외부에서 접근한다 했을
yoo11052.tistory.com
https://watch-n-learn.tistory.com/49
[Docker Advanced] Docker Swarm network 개념 이해
Docker Swarm Network : ingress Ingress 네트워크는 서비스의 노드들 간에 로드 밸런싱을 수행하는 Overlay 네트워크이다. Ingress 네트워크는 도커스웜을 init 하거나 join 할 때 자동으로 생성된다. Docker Swarm에
watch-n-learn.tistory.com
Overview of Docker Networking : Let’s connect the containers!
The Networking goals of the containers are conceptualised under a contract between containers and underlying network that forms CNM…
mohittalniya.medium.com
https://serverfault.com/questions/896296/how-does-load-balancing-vip-works-with-overlay-networks
How does load balancing / VIP works with overlay networks?
I'm trying to understand how the built-in Docker load balancing / VIP works with overlay networks. To better explain how I understand this, I've put together a diagram. My hope is that someone can
serverfault.com
0부터 시작하는 Docker Swarm 공부 - 더 자세한 Docker Swarm Network
Ingress Network / Port 지정과 Network / Overlay Network 생성 및 사용 / Swarm Network 구조 & etcd ( 22.08.25 )
velog.io
'docker' 카테고리의 다른 글
| Docker compose를 통한 Nginx, Spring boot, React, Mysql 연동 및 배포 (0) | 2024.04.07 |
|---|---|
| docker compose를 통해 배포해보자(springboot, react, redis) (0) | 2023.11.17 |
| Gradle, 도커(docker)를 통한 springboot3 with mysql 배포(docker-compose) (0) | 2023.05.07 |


